分布式系统的事务处理
当我们在生产线上用一台服务器来提供数据服务的时候,我会遇到如下的两个问题:
1)一台服务器的性能不足以提供足够的能力服务于所有的网络请求。
2)我们总是害怕我们的这台服务器停机,造成服务不可用或是数据丢失。
于是我们不得不对我们的服务器进行扩展,加入更多的机器来分担性能上的问题,以及来解决单点故障问题。 通常,我们会通过两种手段来扩展我们的数据服务:
1)数据分区:就是把数据分块放在不同的服务器上(如:uid % 16,一致性哈希等)。
2)数据镜像:让所有的服务器都有相同的数据,提供相当的服务。
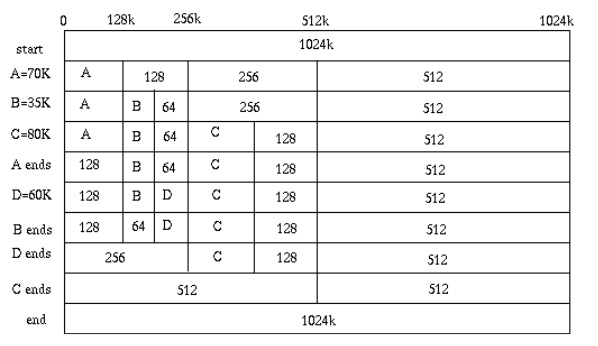
对于第一种情况,我们无法解决数据丢失的问题,单台服务器出问题时,会有部分数据丢失。所以,数据服务的高可用性只能通过第二种方法来完成——数据的冗余存储(一般工业界认为比较安全的备份数应该是3份,如:Hadoop和Dynamo)。 但是,加入更多的机器,会让我们的数据服务变得很复杂,尤其是跨服务器的事务处理,也就是跨服务器的数据一致性。这个是一个很难的问题。 让我们用最经典的Use Case:“A帐号向B帐号汇钱”来说明一下,熟悉RDBMS事务的都知道从帐号A到帐号B需要6个操作:
从A帐 ...

函数式编程
当我们说起函数式编程来说,我们会看到如下函数式编程的长相:
函数式编程的三大特性:
immutable data 不可变数据:像Clojure一样,默认上变量是不可变的,如果你要改变变量,你需要把变量copy出去修改。这样一来,可以让你的程序少很多Bug。因为,程序中的状态不好维护,在并发的时候更不好维护。(你可以试想一下如果你的程序有个复杂的状态,当以后别人改你代码的时候,是很容易出bug的,在并行中这样的问题就更多了)
first class functions:这个技术可以让你的函数就像变量一样来使用。也就是说,你的函数可以像变量一样被创建,修改,并当成变量一样传递,返回或是在函数中嵌套函数。这个有点像Javascript的Prototype(参看Javascript的面向对象编程)
尾递归优化:我们知道递归的害处,那就是如果递归很深的话,stack受不了,并会导致性能大幅度下降。所以,我们使用尾递归优化技术——每次递归时都会重用stack,这样一来能够提升性能,当然,这需要语言或编译器的支持。Python就不支持。
函数式编程的几个技 ...

X-Y Problem
X-Y Problem
对于X-Y Problem的意思如下:
1)有人想解决问题X
2)他觉得Y可能是解决X问题的方法
3)但是他不知道Y应该怎么做
4)于是他去问别人Y应该怎么做?
简而言之,没有去问怎么解决问题X,而是去问解决方案Y应该怎么去实现和操作。于是乎:
1)热心的人们帮助并告诉这个人Y应该怎么搞,但是大家都觉得Y这个方案有点怪异。
2)在经过大量地讨论和浪费了大量的时间后,热心的人终于明白了原始的问题X是怎么一回事。
3)于是大家都发现,Y根本就不是用来解决X的合适的方案。
X-Y Problem最大的严重的问题就是:在一个根本错误的方向上浪费他人大量的时间和精力!
示例
举个两个例子:
Q) 我怎么用Shell取得一个字符串的后3位字符?
A1) 如果这个字符的变量是$foo,你可以这样来 echo ${foo:-3}
A2) 为什么你要取后3位?你想干什么?
Q) 其实我就想取文件的扩展名
A1) 我靠,原来你要干这事,那我的方法不对,文件的扩展名并不保证一定有3位啊。
A1) 如果你的文件必然有扩展名的话, ...

Lua简明教程
这几天系统地学习了一下Lua这个脚本语言,Lua脚本是一个很轻量级的脚本,也是号称性能最高的脚本,用在很多需要性能的地方,比如:游戏脚本,nginx,wireshark的脚本,当你把他的源码下下来编译后,你会发现解释器居然不到200k,这是多么地变态啊(/bin/sh都要1M,MacOS平台),而且能和C语言非常好的互动。我很好奇得浏览了一下Lua解释器的源码,这可能是我看过最干净的C的源码了。
我不想写一篇大而全的语言手册,一方面是因为已经有了(见本文后面的链接),重要的原因是,因为大篇幅的文章会挫败人的学习热情,我始终觉得好的文章读起来就像拉大便一样,能一口气很流畅地搞完,才会让人爽(这也是我为什么不想写书的原因)。所以,这必然又是一篇“入厕文章”,还是那句话,我希望本文能够让大家利用上下班,上厕所大便的时间学习一个技术。呵呵。
相信你现在已经在厕所里脱掉裤子露出屁股已经准备好大便了,那就让我们畅快地排泄吧……
目录
运行
语法
注释
变量
控制语句
while循环
i ...

编程能力与编程年龄
程序员这个职业究竟可以干多少年,在中国这片神奇的土地上,很多人都说只能干到30岁,然后就需要转型,就像《程序员技术练级攻略》这篇文章很多人回复到这种玩法会玩死人的一样。我在很多面试中,问到应聘者未来的规划都能听到好些应聘都说程序员是个青春饭。因为,大多数程序员都认为,编程这个事只能干到30岁,最多35岁吧。每每我听到这样的言论,都让我感到相当的无语,大家都希望能像《21天速成C++》那样速成,好多时候超级有想和他们争论的冲动,但后来想想算了,因为你无法帮助那些只想呆在井底思维封闭而且想走捷径速成的人。
今天,我们又来谈这个老话题,因为我看到一篇论文,但是也一定会有很多人都会找出各种理由来论证这篇论文的是错的,无所谓了,我把这篇文章送给那些和我一样准备为技术和编程执着和坚持的人。
目录
论文
年龄分布图
能力和年龄分布图
年纪大的人是否跟不上新技术
结论
我的一些感受
论文
首先,我们先来看一篇论文《Is Programming Knowledge Related to Age? ...
程序的本质复杂性和元语言抽象
(感谢 @文艺复兴记(todd) 投递此文)
目录
组件复用技术的局限性
程序的本质复杂性
元语言抽象
总结
组件复用技术的局限性
常听到有人讲“我写代码很讲究,一直严格遵循DRY原则,把重复使用的功能都封装成可复用的组件,使得代码简短优雅,同时也易于理解和维护”。显然,DRY原则和组件复用技术是最常见的改善代码质量的方法,不过,在我看来以这类方法为指导,能帮助我们写出“不错的程序”,但还不足以帮助我们写出简短、优雅、易理解、易维护的“好程序”。对于熟悉Martin Fowler《重构》和GoF《设计模式》的程序员,我常常提出这样一个问题帮助他们进一步加深对程序的理解:
如果目标是代码“简短、优雅、易理解、易维护”,组件复用技术是最好的方法吗?这种方法有没有根本性的局限?
虽然基于函数、类等形式的组件复用技术从一定程度上消除了冗余,提升了代码的抽象层次,但是这种技术却有着本质的局限性,其根源在于 每种组件形式都代表了特定的抽象维度,组件复用只能在其维度上进行抽象层次的提升。比如,我们可以把常用的Ha ...
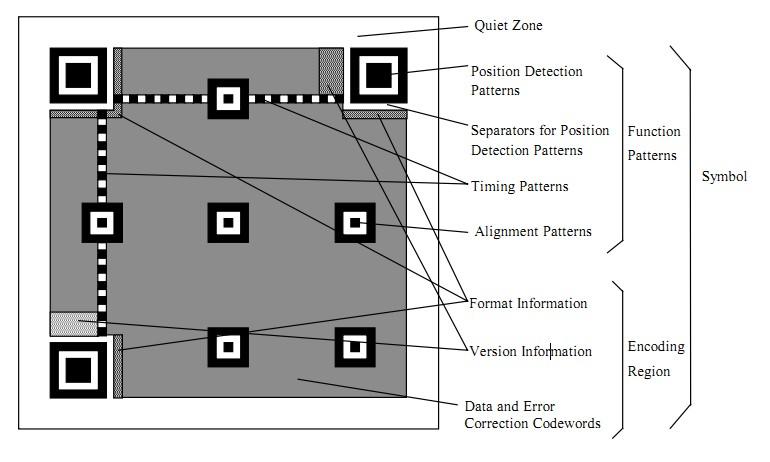
二维码的生成细节和原理
二维码又称QR Code,QR全称Quick Response,是一个近几年来移动设备上超流行的一种编码方式,它比传统的Bar Code条形码能存更多的信息,也能表示更多的数据类型:比如:字符,数字,日文,中文等等。这两天学习了一下二维码图片生成的相关细节,觉得这个玩意就是一个密码算法,在此写一这篇文章 ,揭露一下。供好学的人一同学习之。
关于QR Code Specification,可参看这个PDF:http://raidenii.net/files/datasheets/misc/qr_code.pdf
目录
基础知识
定位图案
功能性数据
数据码和纠错码
数据编码
示例一:数字编码
示例二:字符编码
结束符和补齐符
按8bits重排
补齐码(Padding Bytes)
纠错码
最终编码
穿插放置
Remainder Bits
画二维码图 ...
伙伴分配器的一个极简实现
(感谢网友 @我的上铺叫路遥 投稿)
提起buddy system相信很多人不会陌生,它是一种经典的内存分配算法,大名鼎鼎的Linux底层的内存管理用的就是它。这里不探讨内核这么复杂实现,而仅仅是将该算法抽象提取出来,同时给出一份及其简洁的源码实现,以便定制扩展。
伙伴分配的实质就是一种特殊的“分离适配”,即将内存按2的幂进行划分,相当于分离出若干个块大小一致的空闲链表,搜索该链表并给出同需求最佳匹配的大小。其优点是快速搜索合并(O(logN)时间复杂度)以及低外部碎片(最佳适配best-fit);其缺点是内部碎片,因为按2的幂划分块,如果碰上66单位大小,那么必须划分128单位大小的块。但若需求本身就按2的幂分配,比如可以先分配若干个内存池,在其基础上进一步细分就很有吸引力了。
可以在维基百科上找到该算法的描述,大体如是:
分配内存:
1.寻找大小合适的内存块(大于等于所需大小并且最接近2的幂,比如需要27,实际分配32)
1.如果找到了,分配给应用程序。
2.如果没找到,分出合适的内存块。
1.对半分离出高于所需大小的空闲内存块
2.如果分到最低限度,分配这个大小。
...
C++11的Lambda使用一例:华容道求解
(感谢网友 @bnu_chenshuo 投稿)
华容道是一个有益的智力游戏,游戏规则不再赘述。用计算机求解华容道也是一道不错的编程练习题,为了寻求最少步数,求解程序一般用广度优先搜索算法。华容道的一种常见开局如图 1 所示。
广度优先搜索算法求解华容道的基本步骤:
准备两个“全局变量”,队列 Q 和和集合 S,S 代表“已知局面”。初时 Q 和 S 皆为空。
将初始局面加入队列 Q 的末尾,并将初始局面设为已知。
当队列不为空时,从 Q 的队首取出当前局面 curr。如果队列为空则结束搜索,表明无解。
如果 curr 是最终局面(曹操位于门口,图 2),则结束搜索,否则继续到第 5 步。
考虑 curr 中每个可以移动的棋子,试着上下左右移动一步,得到新局面 next,如果新局面未知(next ∉ S),则把它加入队列 Q,并设为已知。这一步可能产生多个新局面。
回到第2步。
其中“局面已知”并不要求每个棋子的位置相同,而是指棋子的投影的形状相同(代码中用 mask 表示),例如交换图 1 中的张飞和赵云并不产生新局面,这一规定可以大大缩小搜索空间。
以上步骤很容 ...
C++面试中string类的一种正确写法
(感谢网友 @bnu_chenshuo 投稿)
C++ 的一个常见面试题是让你实现一个 String 类,限于时间,不可能要求具备 std::string 的功能,但至少要求能正确管理资源。具体来说:
能像 int 类型那样定义变量,并且支持赋值、复制。
能用作函数的参数类型及返回类型。
能用作标准库容器的元素类型,即 vector/list/deque 的 value_type。(用作 std::map 的 key_type 是更进一步的要求,本文从略)。
换言之,你的 String 能让以下代码编译运行通过,并且没有内存方面的错误。
void foo(String x)
{
}
void bar(const String& x)
{
}
String baz()
{
String ret("world");
return ret;
}
int main()
{
String s0;
String s1("hello");
String s2(s0);
String s3 = s1;
s2 = s1;
foo(s1);
...
C++模板”>>”编译问题与词法消歧设计
(感谢 @文艺复兴记(todd) 投递此文)
在编译理论中,通常将编译过程抽象为5个主要阶段:词法分析(Lexical Analysis),语法分析(Parsing),语义分析(Semantic Analysis),优化(Optimization),代码生成(Code Generation)。这5个阶段类似Unix管道模型,上一个阶段的输出作为下一个阶段的输入。其中,词法分析是根据输入源代码文本流,分割出词,识别类别,产生词法元素(Token)流,如:
int a = 10;
经过词法分析会得到[(Type, “int”), (Identifier, “a”), (AssignOperator, “=”), (IntLiteral, 10)],在后续的语法分析阶段,就会根据这些词法元素匹配相应的语法规则。在我学习编译原理时,教科书中对于词法分析的介绍主要是基于正则表达式的,言下之意就是普通语言的词法规则是可以通过正则表达式描述的。比如,C语言的变量名规则是“包含字母、数字或下划线,并且以字母或下划线开头”,这就可以用正则表达式[a-zA-Z_][a-zA-Z0-9_] ...
数据即代码:元驱动编程
(感谢 @文艺复兴记(todd) 投递此文)
几个小伙伴在考虑下面这个各个语言都会遇到的问题:
问题:设计一个命令行参数解析API
一个好的命令行参数解析库一般涉及到这几个常见的方面:
1) 支持方便地生成帮助信息
2) 支持子命令,比如:git包含了push, pull, commit等多种子命令
3) 支持单字符选项、多字符选项、标志选项、参数选项等多种选项和位置参数
4) 支持选项默认值,比如:–port选项若未指定认为5037
5) 支持使用模式,比如:tar命令的-c和-x是互斥选项,属于不同的使用模式
经过一番考察,小伙伴们发现了这个几个有代表性的API设计:
1. getopt():
getopt()是libc的标准函数,很多语言中都能找到它的移植版本。
//C
while ((c = getopt(argc, argv, "ac:d:")) != -1) {
int this_option_optind = optind ? optind : 1;
switch (c) {
case 'a':
printf ("o ...

数据的游戏:冰与火
我对数据挖掘和机器学习是新手,从去年7月份在Amazon才开始接触,而且还是因为工作需要被动接触的,以前都没有接触过,做的是需求预测机器学习相关的。后来,到了淘宝后,自己凭兴趣主动地做了几个月的和用户地址相关数据挖掘上的工作,有一些浅薄的心得。下面这篇文章主要是我做为一个新人仅从事数据方面技术不到10个月的一些心得,也许对你有用,也许很傻,不管怎么样,欢迎指教和讨论。
另外,注明一下,这篇文章的标题模仿了一个美剧《权力的游戏:冰与火之歌》。在数据的世界里,我们看到了很多很牛,很强大也很有趣的案例。但是,数据就像一个王座一样,像征着一种权力和征服,但登上去的路途一样令人胆颤。
目录
数据挖掘中的三种角色
数据的质量
案例一:数据的标准
案例二:数据的准确
数据的业务场景
数据的分析结果
总结
数据挖掘中的三种角色
在Amazon里从事机器学习的工作时,我注意到了Amazon玩数据的三种角色。
Data Analyzer:数据分析员。这类人的人主要是分析数据的,从数据中找到一些规 ...
7个示例科普CPU Cache
(感谢网友 @我的上铺叫路遥 翻译投稿)
CPU cache一直是理解计算机体系架构的重要知识点,也是并发编程设计中的技术难点,而且相关参考资料如同过江之鲫,浩瀚繁星,阅之如临深渊,味同嚼蜡,三言两语难以入门。正好网上有人推荐了微软大牛Igor Ostrovsky一篇博文《漫游处理器缓存效应》,文章不仅仅用7个最简单的源码示例就将CPU cache的原理娓娓道来,还附加图表量化分析做数学上的佐证,个人感觉这种案例教学的切入方式绝对是俺的菜,故而忍不住贸然译之,以飨列位看官。
原文地址:Gallery of Processor Cache Effects
大多数读者都知道cache是一种快速小型的内存,用以存储最近访问内存位置。这种描述合理而准确,但是更多地了解一些处理器缓存工作中的“烦人”细节对于理解程序运行性能有很大帮助。
在这篇博客中,我将运用代码示例来详解cache工作的方方面面,以及对现实世界中程序运行产生的影响。
下面的例子都是用C#写的,但语言的选择同程序运行状况以及得出的结论几乎没什么影响。
目录
示例1:内存访问和运行 ...

加班与效率
微博上看到了这么一个贴子,就像以前在《腾讯,竞争力 和 用户体验》中批评过腾讯说自己的核心竞争力是员工加班一样,我顺着Winter的回复也批评了一下这个微博——
“靠加班超越对手?!劳动密集型么?我要是对手的话,我就来趁机挖人了,直接摁死你……//@寒冬winter: 当一个管理者的智慧无法衡量一支团队的产出的时候,他就会把“工时”当做最后的救命稻草,死死抱住——这是他唯一听得懂的东西了。”
然后,@玄了个澄的在微博里at我说,他在微信里看了@Fenng 关于加班的言论,希望我评论一下。我看了一下大辉的文章,虽然写得有点散乱,但是我和他的一些观点还是很类似的,我主要在这里加强一下我的看法。
关于加班
认为加班是公司的核心竞争力,或是超越对手的手段,是一种相当 Ridiculous 的想法。这说明管理者们已经想不到自己公司的核心价值了。
是的,这些靠堆功能没有灵魂的产品的价值就只剩下比谁跑得快了。他们愚蠢和思维有限的大脑里已经区分不出来,“跑得快”和“跑得好”的差别了。产品的发展不是短跑,而是长跑,甚至更像是登山,登山比的不是快,而比的是策略,比的是意志,目的是登顶。并不 ...
类型的本质和函数式实现
(感谢 @文艺复兴记(todd) 投递此文)
在上一篇文章《二叉树迭代器算法》中,我介绍了一种基于栈的二叉树迭代器实现。程序设计语言和Haskell大牛@九瓜 在看过之后评论到:
这里用了 stack 来做,有点偷懒,所以错失了一个抽象思考机会。如果我们能够理解二叉树到线性表的转换过程,完全可以把 Iterator 当作抽象的线性表来看,只要定义了关于 Iterator 的 empty, singleton, 还有 append 操作,实现二叉树的 Iterator 就变得非常直观。
“错失了一个抽象思考机会”是什么意思呢?我理解九瓜的意思是基于栈的实现虽然是正确的,但它缺乏对于迭代器类型本质的理解,不具有通用性。如果能对迭代器进行合适地抽象就可以像二叉树递归遍历一样自然地得出二叉树迭代器,甚至其他更复杂的数据结构,只要我们能写出它的遍历算法,迭代器算法都可以自然推出。
目录
类型的本质
类型的函数式实现
函数式二叉树迭代器
总结
类型的本质
九瓜提到了通过empty, singleton和append操作对 ...
C语言全局变量那些事儿
(感谢网友 @我的上铺叫路遥 投稿)
作为一名程序员,如果说沉迷一门编程语言算作一种乐趣的话,那么与此同时反过来去黑一门编程语言就是这种乐趣的升华。今天我们就来黑一把C语言,好好展示一下这门经典语言令人抓狂的一面。
我们知道,全局变量是C语言语法和语义中一个很重要的知识点,首先它的存在意义需要从三个不同角度去理解:对于程序员来说,它是一个记录内容的变量(variable);对于编译/链接器来说,它是一个需要解析的符号(symbol);对于计算机来说,它可能是具有地址的一块内存(memory)。其次是语法/语义:从作用域上看,带static关键字的全局变量范围只能限定在文件里,否则会外联到整个模块和项目中;从生存期来看,它是静态的,贯穿整个程序或模块运行期间(注意,正是跨单元访问和持续生存周期这两个特点使得全局变量往往成为一段受攻击代码的突破口,了解这一点十分重要);从空间分配上看,定义且初始化的全局变量在编译时在数据段(.data)分配空间,定义但未初始化的全局变量暂存(tentative definition)在.bss段,编译时自动清零,而仅仅是声明的全局变量 ...
二叉树迭代器算法
(感谢 @文艺复兴记(todd) 投递此文)
二叉树(Binary Tree)的前序、中序和后续遍历是算法和数据结构中的基本问题,基于递归的二叉树遍历算法更是递归的经典应用。
假设二叉树结点定义如下:
// C++
struct Node {
int value;
Node *left;
Node *right;
}
中序递归遍历算法:
// C++
void inorder_traverse(Node *node) {
if (NULL != node->left) {
inorder_traverse(node->left);
}
do_something(node);
if (NULL != node->right) {
inorder_traverse(node->right);
}
}
前序和后序遍历算法类似。
但是,仅有遍历算法是不够的,在许多应用中,我们还需要对遍历本身进行抽象。假如有一个求和的函数sum,我们希望它能应用于链表,数组 ...
Alan Cox:大教堂、市集与市议会
(感谢网友 @我的上铺叫路遥 投稿)
在网上搜到的Cox大叔于1998年在开源社区写的一篇文章,当时很轰动,明眼人一看就知道是针对ESR那篇《大教堂与市集》,从中可见Alan在项目管理风格上乃至个人性格上都与ESR、Linus等人不同之处。顺便说一句,Alan现在出于“家庭原因”已经离开了Linux项目,他曾经评价Linus是a good developer but a terrible engineer,甚至在Google+上直接说Linus就是一a*sh**e。不管如何,两位曾经十余年里并肩战斗惺惺相惜的大牛就此分道扬镳还是惹人唏嘘。
言归正传,以下为slashdot收录的英文原文:Cathedrals, Bazaars and the Town Council。
以下是一些我对市集模式的想法,我认为这值得分享,这种模式会教你如何完全毁掉一个自由软件项目。我还举了一个我称之为“市议会”(Town Council)效应的实例(虽然那些市议员们可不这么认为,注:此处指Linux项目开发者)。
关于软件开发人员,你必须去了解一些情况。首先要了解的是真正优秀的程序员相 ...

IoC/DIP其实是一种管理思想
关于IoC的的概念提出来已经很多年了,其被用于一种面象对像的设计。我在这里再简单的回顾一下这个概念。我先谈技术,再说管理。
话说,我们有一个开关要控制一个灯的开和关这两个动作,最常见也是最没有技术含量的实现会是这个样子:
然后,有一天,我们发现需要对灯泡扩展一下,于是我们做了个抽象类:
但是,如果有一天,我们发现这个开关可能还要控制别的不单单是灯泡的东西,我们就发现这个开关耦合了灯泡这种类别,非常不利于我们的扩展,于是反转控制出现了。
就像现实世界一样,造开关的工厂根本不关心要控制的东西是什么,它只做一个开关应该做好的事,就是把电接通,把电断开(不管是手动的,还是声控的,还是光控,还是遥控的),而我们的造各种各样的灯泡(不管是日关灯,白炽灯)的工厂也不关心你用什么样的开关,反正我只管把灯的电源接口给做出来,然后,开关厂和电灯厂依赖于一个标准的通电和断电的接口。于是产生了IoC控制反转,如下图:
所谓控制反转的意思是,开关从以前的设备的专用开关,转变到了控制电源的开关,而以前的设备要反过来依赖于开关厂声明的电源连接接口。只要符合开关厂定义的电源连接的接口,这个开关可以控制所有 ...