eBPF 介绍
很早前就想写一篇关于eBPF的文章,但是迟迟没有动手,这两天有点时间,所以就来写一篇,这文章主要还是简单的介绍eBPF 是用来干什么的,并通过几个示例来介绍是怎么玩的,这个技术非常非常之强,Linux 操作系统的观测性实在是太强大了,并在 BCC 加持下变得一览无余。这个技术不是一般的运维人员或是系统管理员可以驾驭的,这个还是要有底层系统知识并有一定开发能力的技术人员才能驾驭的了的。我在这篇文章的最后给了个彩蛋。
目录
介绍
用途
工作原理
示例
延伸阅读
彩蛋
介绍
eBPF(extened Berkeley Packet Filter)是一种内核技术,它允许开发人员在不修改内核代码的情况下运行特定的功能。eBPF 的概念源自于 Berkeley Packet Filter(BPF),后者是由贝尔实验室开发的一种网络过滤器,可以捕获和过滤网络数据包。
出于对更好的 Linux 跟踪工具的需求,eBPF 从 dtrace中汲取灵感,dtrace 是一种主要用于 Solaris 和 BSD 操作系统的动态 ...

API设计原则 – Qt官网的设计实践总结
(感谢好友 @李鼎 翻译此文)
原文链接:API Design Principles – Qt Wiki
基于Gary的影响力上 Gary Gao 的译文稿:C++的API设计指导
译序
Qt的设计水准在业界很有口碑,一致、易于掌握和强大的API是Qt最著名的优点之一。此文既是Qt官网上的API设计指导准则,也是Qt在API设计上的实践总结。虽然Qt用的是C++,但其中设计原则和思考是具有普适性的(如果你对C++还不精通,可以忽略与C++强相关或是过于细节的部分,仍然可以学习或梳理关于API设计最有价值的内容)。整个篇幅中有很多示例,是关于API设计一篇难得的好文章。
需要注意的是,这篇Wiki有一些内容并不完整,所以,可能会有一些阅读上的问题,我们对此做了一些相关的注释。
PS:翻译中肯定会有不足和不对之处,欢迎评论&交流;另译文源码在GitHub的这个仓库中,可以提交Issue/Fork后提交代码来建议/指正。
API设计原则
一致、易于掌握和强大的API是Qt最著名的优点之一。此文总结了我们在设计Qt风格API的过程中所积累 ...

如何重构“箭头型”代码
本文主要起因是,一次在微博上和朋友关于嵌套好几层的if-else语句的代码重构的讨论(微博原文),在微博上大家有各式各样的问题和想法。按道理来说这些都是编程的基本功,似乎不太值得写一篇文章,不过我觉得很多东西可以从一个简单的东西出发,到达本质,所以,我觉得有必要在这里写一篇的文章。不一定全对,只希望得到更多的讨论,因为有了更深入的讨论才能进步。
文章有点长,我在文章最后会给出相关的思考和总结陈词,你可以跳到结尾。
所谓箭头型代码,基本上来说就是下面这个图片所示的情况。
那么,这样“箭头型”的代码有什么问题呢?看上去也挺好看的,有对称美。但是……
关于箭头型代码的问题有如下几个:
1)我的显示器不够宽,箭头型代码缩进太狠了,需要我来回拉水平滚动条,这让我在读代码的时候,相当的不舒服。
2)除了宽度外还有长度,有的代码的if-else里的if-else里的if-else的代码太多,读到中间你都不知道中间的代码是经过了什么样的层层检查才来到这里的。
总而言之,“箭头型代码”如果嵌套太多,代码太长的话,会相当容易让维护代码的人(包括自己)迷失在代码中,因为看到最内层的代码时,你已经不知道 ...

Cuckoo Filter:设计与实现
(感谢网友 @我的上铺叫路遥 投稿)
对于海量数据处理业务,我们通常需要一个索引数据结构,用来帮助查询,快速判断数据记录是否存在,这种数据结构通常又叫过滤器(filter)。考虑这样一个场景,上网的时候需要在浏览器上输入URL,这时浏览器需要去判断这是否一个恶意的网站,它将对本地缓存的成千上万的URL索引进行过滤,如果不存在,就放行,如果(可能)存在,则向远程服务端发起验证请求,并回馈客户端给出警告。
索引的存储又分为有序和无序,前者使用关联式容器,比如B树,后者使用哈希算法。这两类算法各有优劣:比如,关联式容器时间复杂度稳定O(logN),且支持范围查询;又比如哈希算法的查询、增删都比较快O(1),但这是在理想状态下的情形,遇到碰撞严重的情况,哈希算法的时间复杂度会退化到O(n)。因此,选择一个好的哈希算法是很重要的。
时下一个非常流行的哈希索引结构就是bloom filter,它类似于bitmap这样的hashset,所以空间利用率很高。其独特的地方在于它使用多个哈希函数来避免哈希碰撞,如图所示(来源wikipedia),bit数组初始化为全0,插入x时,x ...

vfork 挂掉的一个问题
在知乎上,有个人问了这样的一个问题——为什么vfork的子进程里用return,整个程序会挂掉,而且exit()不会?并给出了如下的代码,下面的代码一运行就挂掉了,但如果把子进程的return改成exit(0)就没事。
我受邀后本来不想回答这个问题的,因为这个问题明显就是RTFM的事,后来,发现这个问题放在那里好长时间,而挂在下面的几个答案又跑偏得比较严重,我觉得可能有些朋友看到那样的答案会被误导,所以就上去回答了一下这个问题。
下面我把问题和我的回答发布在这里,也供更多的人查看。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void) {
int var;
var = 88;
if ((pid = vfork()) < 0) {
printf("vfork error");
exit(-1);
} else if (pid == 0) { /* 子进程 */
var++; ...

Leetcode 编程训练
Leetcode这个网站上的题都是一些经典的公司用来面试应聘者的面试题,很多人通过刷这些题来应聘一些喜欢面试算法的公司,比如:Google、微软、Facebook、Amazon之类的这些公司,基本上是应试教育的功利主义。
我做这些题目的不是为了要去应聘这些公司,而是为了锻炼一下自己的算法和编程能力。因为我开始工作的时候基本没有这样的训练算法和编程的网站,除了大学里的“算法和数据结构”里的好些最基础最基础的知识,基本上没有什么训练。所以,当我看到有人在做这些题的时候,我也蠢蠢欲动地想去刷一下。
于是,我花了3-4个月的业余时间,我把Leetcode的154道题全部做完了。(这也是最近我没有太多的时间来写博客的原因,你可以看到我之前做的那个活动中有几个算法题来自于Leetcode)有人说我时间太多了,这里声明一下,我基本上都是利用了晚上10点以后的时间来做这些题的。
LeetCode的题大致分成两类:
1)基础算法的知识。这些题里面有大量的算法题,解这些题都是有套路的,不是用递归(深度优先DFS,广度优先BFS),就是要用动态规划(Dynamic Programming),或是拆半查找( ...
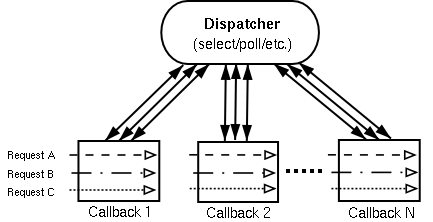
State Threads 回调终结者
(感谢网友 @我的上铺叫路遥 投稿)
上回写了篇《一个“蝇量级”C语言协程库》,推荐了一下Protothreads,通过coroutine模拟了用户级别的multi-threading模型,虽然本身足够“轻”,杜绝了系统开销,但这个库本身应用场合主要是内存限制的嵌入式领域,提供原生态组件太少,使用限制太多,比如依赖其它调用产生阻塞等。
这回又替大家在开源界淘了个宝,推荐一个轻量级网络应用框架State Threads(以下简称ST),总共也就3000行C代码,跟Protothreads不同在于ST针对的就是高性能可扩展服务器领域(值得一提的是Protothreads官网参考链接上第一条就是ST的官网)。在其FAQ页面上一句引用”Perfection is achieved not when there is nothing more to add, but rather when there is nothing more to take away.”可以视为开发人员对ST源码质量的自信。
目录
历史渊源
基于事件驱动状态机(E ...

C语言的整型溢出问题
整型溢出有点老生常谈了,bla, bla, bla… 但似乎没有引起多少人的重视。整型溢出会有可能导致缓冲区溢出,缓冲区溢出会导致各种黑客攻击,比如最近OpenSSL的heartbleed事件,就是一个buffer overread的事件。在这里写下这篇文章,希望大家都了解一下整型溢出,编译器的行为,以及如何防范,以写出更安全的代码。
目录
什么是整型溢出
整型溢出的危害
示例一:整形溢出导致死循环
示例二:整形转型时的溢出
示例三:分配内存
示例四:缓冲区溢出导致安全问题
示例五:size_t 的溢出
关于编译器的行为
编译器优化
花絮:编译器的彩蛋
正确检测整型溢出
二分取中搜索算法中的溢出
上溢出和下溢出的检查
其它
什么是整型溢出
C语言的整型问题相信大家并不陌生了。对于整型溢出,分为无符号整型溢出和有符号整型溢出。
对于unsigned整型溢出,C的规范是有定义 ...

C语言结构体里的成员数组和指针
单看这文章的标题,你可能会觉得好像没什么意思。你先别下这个结论,相信这篇文章会对你理解C语言有帮助。这篇文章产生的背景是在微博上,看到@Laruence同学出了一个关于C语言的题,微博链接。微博截图如下。我觉得好多人对这段代码的理解还不够深入,所以写下了这篇文章。
为了方便你把代码copy过去编译和调试,我把代码列在下面:
#include <stdio.h>
struct str{
int len;
char s[0];
};
struct foo {
struct str *a;
};
int main(int argc, char** argv) {
struct foo f={0};
if (f.a->s) {
printf( f.a->s);
}
return 0;
}
你编译一下上面的代码,在VC++和GCC下都会在14行的printf处crash掉你的程序。@Laruence 说这个是个经典的坑,我觉得这怎么会是经典的坑呢?上面这代码,你一定会问,为什么if ...
由苹果的低级Bug想到的
2014年2月22日,在这个“这么二”的日子里,苹果公司推送了 iOS 7.0.6(版本号11B651)修复了 SSL 连接验证的一个 bug。官方网页在这里:http://support.apple.com/kb/HT6147,网页中如下描述:
Impact: An attacker with a privileged network position may capture or modify data in sessions protected by SSL/TLS
Description: Secure Transport failed to validate the authenticity of the connection. This issue was addressed by restoring missing validation steps.
也就是说,这个bug会引起中间人攻击,bug的描述中说,这个问题是因为miss了对连接认证的合法性检查的步骤。
这里多说一句,一旦网上发生任何的和SSL/TL相关 ...
一个“蝇量级” C 语言协程库
(感谢网友 @我的上铺叫路遥 投稿)
协程(coroutine)顾名思义就是“协作的例程”(co-operative routines)。跟具有操作系统概念的线程不一样,协程是在用户空间利用程序语言的语法语义就能实现逻辑上类似多任务的编程技巧。实际上协程的概念比线程还要早,按照 Knuth 的说法“子例程是协程的特例”,一个子例程就是一次子函数调用,那么实际上协程就是类函数一样的程序组件,你可以在一个线程里面轻松创建数十万个协程,就像数十万次函数调用一样。只不过子例程只有一个调用入口起始点,返回之后就结束了,而协程入口既可以是起始点,又可以从上一个返回点继续执行,也就是说协程之间可以通过 yield 方式转移执行权,对称(symmetric)、平级地调用对方,而不是像例程那样上下级调用关系。当然 Knuth 的“特例”指的是协程也可以模拟例程那样实现上下级调用关系,这就叫非对称协程(asymmetric coroutines)。
目录
基于事件驱动模型
“蝇量级”的协程库
C 语言的“yield 语义”
Protot ...
伙伴分配器的一个极简实现
(感谢网友 @我的上铺叫路遥 投稿)
提起buddy system相信很多人不会陌生,它是一种经典的内存分配算法,大名鼎鼎的Linux底层的内存管理用的就是它。这里不探讨内核这么复杂实现,而仅仅是将该算法抽象提取出来,同时给出一份及其简洁的源码实现,以便定制扩展。
伙伴分配的实质就是一种特殊的“分离适配”,即将内存按2的幂进行划分,相当于分离出若干个块大小一致的空闲链表,搜索该链表并给出同需求最佳匹配的大小。其优点是快速搜索合并(O(logN)时间复杂度)以及低外部碎片(最佳适配best-fit);其缺点是内部碎片,因为按2的幂划分块,如果碰上66单位大小,那么必须划分128单位大小的块。但若需求本身就按2的幂分配,比如可以先分配若干个内存池,在其基础上进一步细分就很有吸引力了。
可以在维基百科上找到该算法的描述,大体如是:
分配内存:
1.寻找大小合适的内存块(大于等于所需大小并且最接近2的幂,比如需要27,实际分配32)
1.如果找到了,分配给应用程序。
2.如果没找到,分出合适的内存块。
1.对半分离出高于所需大小的空闲内存块
2.如果分到最低限度,分配这个大小。
...
C++11的Lambda使用一例:华容道求解
(感谢网友 @bnu_chenshuo 投稿)
华容道是一个有益的智力游戏,游戏规则不再赘述。用计算机求解华容道也是一道不错的编程练习题,为了寻求最少步数,求解程序一般用广度优先搜索算法。华容道的一种常见开局如图 1 所示。
广度优先搜索算法求解华容道的基本步骤:
准备两个“全局变量”,队列 Q 和和集合 S,S 代表“已知局面”。初时 Q 和 S 皆为空。
将初始局面加入队列 Q 的末尾,并将初始局面设为已知。
当队列不为空时,从 Q 的队首取出当前局面 curr。如果队列为空则结束搜索,表明无解。
如果 curr 是最终局面(曹操位于门口,图 2),则结束搜索,否则继续到第 5 步。
考虑 curr 中每个可以移动的棋子,试着上下左右移动一步,得到新局面 next,如果新局面未知(next ∉ S),则把它加入队列 Q,并设为已知。这一步可能产生多个新局面。
回到第2步。
其中“局面已知”并不要求每个棋子的位置相同,而是指棋子的投影的形状相同(代码中用 mask 表示),例如交换图 1 中的张飞和赵云并不产生新局面,这一规定可以大大缩小搜索空间。
以上步骤很容 ...
C++面试中string类的一种正确写法
(感谢网友 @bnu_chenshuo 投稿)
C++ 的一个常见面试题是让你实现一个 String 类,限于时间,不可能要求具备 std::string 的功能,但至少要求能正确管理资源。具体来说:
能像 int 类型那样定义变量,并且支持赋值、复制。
能用作函数的参数类型及返回类型。
能用作标准库容器的元素类型,即 vector/list/deque 的 value_type。(用作 std::map 的 key_type 是更进一步的要求,本文从略)。
换言之,你的 String 能让以下代码编译运行通过,并且没有内存方面的错误。
void foo(String x)
{
}
void bar(const String& x)
{
}
String baz()
{
String ret("world");
return ret;
}
int main()
{
String s0;
String s1("hello");
String s2(s0);
String s3 = s1;
s2 = s1;
foo(s1);
...
C++模板”>>”编译问题与词法消歧设计
(感谢 @文艺复兴记(todd) 投递此文)
在编译理论中,通常将编译过程抽象为5个主要阶段:词法分析(Lexical Analysis),语法分析(Parsing),语义分析(Semantic Analysis),优化(Optimization),代码生成(Code Generation)。这5个阶段类似Unix管道模型,上一个阶段的输出作为下一个阶段的输入。其中,词法分析是根据输入源代码文本流,分割出词,识别类别,产生词法元素(Token)流,如:
int a = 10;
经过词法分析会得到[(Type, “int”), (Identifier, “a”), (AssignOperator, “=”), (IntLiteral, 10)],在后续的语法分析阶段,就会根据这些词法元素匹配相应的语法规则。在我学习编译原理时,教科书中对于词法分析的介绍主要是基于正则表达式的,言下之意就是普通语言的词法规则是可以通过正则表达式描述的。比如,C语言的变量名规则是“包含字母、数字或下划线,并且以字母或下划线开头”,这就可以用正则表达式[a-zA-Z_][a-zA-Z0-9_] ...
数据即代码:元驱动编程
(感谢 @文艺复兴记(todd) 投递此文)
几个小伙伴在考虑下面这个各个语言都会遇到的问题:
问题:设计一个命令行参数解析API
一个好的命令行参数解析库一般涉及到这几个常见的方面:
1) 支持方便地生成帮助信息
2) 支持子命令,比如:git包含了push, pull, commit等多种子命令
3) 支持单字符选项、多字符选项、标志选项、参数选项等多种选项和位置参数
4) 支持选项默认值,比如:–port选项若未指定认为5037
5) 支持使用模式,比如:tar命令的-c和-x是互斥选项,属于不同的使用模式
经过一番考察,小伙伴们发现了这个几个有代表性的API设计:
1. getopt():
getopt()是libc的标准函数,很多语言中都能找到它的移植版本。
//C
while ((c = getopt(argc, argv, "ac:d:")) != -1) {
int this_option_optind = optind ? optind : 1;
switch (c) {
case 'a':
printf ("o ...
C语言全局变量那些事儿
(感谢网友 @我的上铺叫路遥 投稿)
作为一名程序员,如果说沉迷一门编程语言算作一种乐趣的话,那么与此同时反过来去黑一门编程语言就是这种乐趣的升华。今天我们就来黑一把C语言,好好展示一下这门经典语言令人抓狂的一面。
我们知道,全局变量是C语言语法和语义中一个很重要的知识点,首先它的存在意义需要从三个不同角度去理解:对于程序员来说,它是一个记录内容的变量(variable);对于编译/链接器来说,它是一个需要解析的符号(symbol);对于计算机来说,它可能是具有地址的一块内存(memory)。其次是语法/语义:从作用域上看,带static关键字的全局变量范围只能限定在文件里,否则会外联到整个模块和项目中;从生存期来看,它是静态的,贯穿整个程序或模块运行期间(注意,正是跨单元访问和持续生存周期这两个特点使得全局变量往往成为一段受攻击代码的突破口,了解这一点十分重要);从空间分配上看,定义且初始化的全局变量在编译时在数据段(.data)分配空间,定义但未初始化的全局变量暂存(tentative definition)在.bss段,编译时自动清零,而仅仅是声明的全局变量 ...
二叉树迭代器算法
(感谢 @文艺复兴记(todd) 投递此文)
二叉树(Binary Tree)的前序、中序和后续遍历是算法和数据结构中的基本问题,基于递归的二叉树遍历算法更是递归的经典应用。
假设二叉树结点定义如下:
// C++
struct Node {
int value;
Node *left;
Node *right;
}
中序递归遍历算法:
// C++
void inorder_traverse(Node *node) {
if (NULL != node->left) {
inorder_traverse(node->left);
}
do_something(node);
if (NULL != node->right) {
inorder_traverse(node->right);
}
}
前序和后序遍历算法类似。
但是,仅有遍历算法是不够的,在许多应用中,我们还需要对遍历本身进行抽象。假如有一个求和的函数sum,我们希望它能应用于链表,数组 ...

Alan Cox:单向链表中prev指针的妙用
Alan Cox
(感谢网友 @我的上铺叫路遥 投稿)
之前发过一篇二级指针操作单向链表的例子,显示了C语言指针的灵活性,这次再探讨一个指针操作链表的例子,而且是一种完全不同的用法。
这个例子是linux-1.2.13网络协议栈里的,关于链表遍历&数据拷贝的一处实现。源文件是/net/inet/dev.c,你可以从kernel.org官网上下载。
从最早的0.96c版本开始,linux网络部分一直采取TCP/IP协议族实现,这是最为广泛应用的网络协议,整个架构就是经典的OSI七层模型的描述,其中dev.c是属于链路层实现。从功能上看,其位于网络设备驱动程序和网络层协议实现模块之间,作为二者之间的数据包传输通道,一种接口模块而存在——对驱动层的接口函数netif_rx, 以及对网络层的接口函数net_bh。前者提供给驱动模块的中断例程调用,用于链路数据帧的封装;后者作为驱动中断例程底半部(buttom half),用于对数据帧的解析处理并向上层传送。
为了便于理解,这里补充一下网络通信原理和linux驱动中断机制的背景知识。从最底层的物理层说 ...
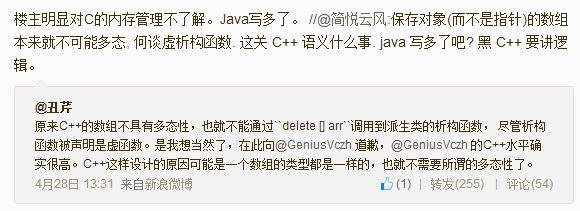
“C++的数组不支持多态”?
先是在微博上看到了个微博和云风的评论,然后我回了“楼主对C的内存管理不了解”。
后来引发了很多人的讨论,大量的人又借机来黑C++,比如:
//@Baidu-ThursdayWang:这不就c++弱爆了的地方吗,需要记忆太多东西
//@编程浪子张发财:这个跟C关系真不大。不过我得验证一下,感觉真的不应该是这样的。如果基类的析构这种情况不能 调用,就太弱了。
//@程序元:现在看来,当初由于毅力不够而没有深入纠缠c++语言特性的各种犄角旮旯的坑爹细枝末节,实是幸事。为现在还沉浸于这些诡异特性并乐此不疲的同志们感到忧伤。
然后,也出现了一些乱七八糟的理解:
//@BA5BO: 数组是基于拷贝的,而多态是基于指针的,派生类赋值给基类数组只是拷贝复制了一个基类新对象,当然不需要派生类析构函数
//@编程浪子张发财:我突然理解是怎么回事了,这种情况下数组中各元素都是等长结构体,类型必须一致,的确没法多态。这跟C#和java不同。后两者对于引用类型存放的是对象指针。
等等,看来我必需要写一篇博客以正视听了。
因为没有看到上下文,我就猜测讨论的可能会是下面这两种情况之一:
1) ...