如何重构“箭头型”代码
本文主要起因是,一次在微博上和朋友关于嵌套好几层的if-else语句的代码重构的讨论(微博原文),在微博上大家有各式各样的问题和想法。按道理来说这些都是编程的基本功,似乎不太值得写一篇文章,不过我觉得很多东西可以从一个简单的东西出发,到达本质,所以,我觉得有必要在这里写一篇的文章。不一定全对,只希望得到更多的讨论,因为有了更深入的讨论才能进步。
文章有点长,我在文章最后会给出相关的思考和总结陈词,你可以跳到结尾。
所谓箭头型代码,基本上来说就是下面这个图片所示的情况。
那么,这样“箭头型”的代码有什么问题呢?看上去也挺好看的,有对称美。但是……
关于箭头型代码的问题有如下几个:
1)我的显示器不够宽,箭头型代码缩进太狠了,需要我来回拉水平滚动条,这让我在读代码的时候,相当的不舒服。
2)除了宽度外还有长度,有的代码的if-else里的if-else里的if-else的代码太多,读到中间你都不知道中间的代码是经过了什么样的层层检查才来到这里的。
总而言之,“箭头型代码”如果嵌套太多,代码太长的话,会相当容易让维护代码的人(包括自己)迷失在代码中,因为看到最内层的代码时,你已经不知道 ...

C语言的整型溢出问题
整型溢出有点老生常谈了,bla, bla, bla… 但似乎没有引起多少人的重视。整型溢出会有可能导致缓冲区溢出,缓冲区溢出会导致各种黑客攻击,比如最近OpenSSL的heartbleed事件,就是一个buffer overread的事件。在这里写下这篇文章,希望大家都了解一下整型溢出,编译器的行为,以及如何防范,以写出更安全的代码。
目录
什么是整型溢出
整型溢出的危害
示例一:整形溢出导致死循环
示例二:整形转型时的溢出
示例三:分配内存
示例四:缓冲区溢出导致安全问题
示例五:size_t 的溢出
关于编译器的行为
编译器优化
花絮:编译器的彩蛋
正确检测整型溢出
二分取中搜索算法中的溢出
上溢出和下溢出的检查
其它
什么是整型溢出
C语言的整型问题相信大家并不陌生了。对于整型溢出,分为无符号整型溢出和有符号整型溢出。
对于unsigned整型溢出,C的规范是有定义 ...
一个“蝇量级” C 语言协程库
(感谢网友 @我的上铺叫路遥 投稿)
协程(coroutine)顾名思义就是“协作的例程”(co-operative routines)。跟具有操作系统概念的线程不一样,协程是在用户空间利用程序语言的语法语义就能实现逻辑上类似多任务的编程技巧。实际上协程的概念比线程还要早,按照 Knuth 的说法“子例程是协程的特例”,一个子例程就是一次子函数调用,那么实际上协程就是类函数一样的程序组件,你可以在一个线程里面轻松创建数十万个协程,就像数十万次函数调用一样。只不过子例程只有一个调用入口起始点,返回之后就结束了,而协程入口既可以是起始点,又可以从上一个返回点继续执行,也就是说协程之间可以通过 yield 方式转移执行权,对称(symmetric)、平级地调用对方,而不是像例程那样上下级调用关系。当然 Knuth 的“特例”指的是协程也可以模拟例程那样实现上下级调用关系,这就叫非对称协程(asymmetric coroutines)。
目录
基于事件驱动模型
“蝇量级”的协程库
C 语言的“yield 语义”
Protot ...
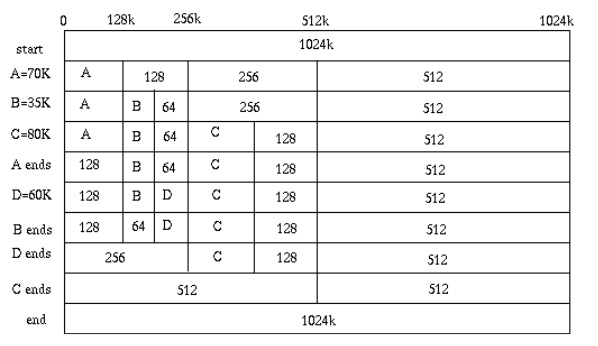
伙伴分配器的一个极简实现
(感谢网友 @我的上铺叫路遥 投稿)
提起buddy system相信很多人不会陌生,它是一种经典的内存分配算法,大名鼎鼎的Linux底层的内存管理用的就是它。这里不探讨内核这么复杂实现,而仅仅是将该算法抽象提取出来,同时给出一份及其简洁的源码实现,以便定制扩展。
伙伴分配的实质就是一种特殊的“分离适配”,即将内存按2的幂进行划分,相当于分离出若干个块大小一致的空闲链表,搜索该链表并给出同需求最佳匹配的大小。其优点是快速搜索合并(O(logN)时间复杂度)以及低外部碎片(最佳适配best-fit);其缺点是内部碎片,因为按2的幂划分块,如果碰上66单位大小,那么必须划分128单位大小的块。但若需求本身就按2的幂分配,比如可以先分配若干个内存池,在其基础上进一步细分就很有吸引力了。
可以在维基百科上找到该算法的描述,大体如是:
分配内存:
1.寻找大小合适的内存块(大于等于所需大小并且最接近2的幂,比如需要27,实际分配32)
1.如果找到了,分配给应用程序。
2.如果没找到,分出合适的内存块。
1.对半分离出高于所需大小的空闲内存块
2.如果分到最低限度,分配这个大小。
...

无锁队列的实现
————注:本文于2019年11月4日更新————
关于无锁队列的实现,网上有很多文章,虽然本文可能和那些文章有所重复,但是我还是想以我自己的方式把这些文章中的重要的知识点串起来和大家讲一讲这个技术。下面开始正文。
目录
关于CAS等原子操作
无锁队列的链表实现
CAS的ABA问题
解决ABA的问题
用数组实现无锁队列
小结
关于CAS等原子操作
在开始说无锁队列之前,我们需要知道一个很重要的技术就是CAS操作——Compare & Set,或是 Compare & Swap,现在几乎所有的CPU指令都支持CAS的原子操作,X86下对应的是 CMPXCHG 汇编指令。有了这个原子操作,我们就可以用其来实现各种无锁(lock free)的数据结构。
这个操作用C语言来描述就是下面这个样子:(代码来自Wikipedia的Compare And Swap词条)意思就是说,看一看内存*reg里的值是不是oldval,如果是的话,则对其赋值newval。
int compa ...
又一个有趣的面试题
大家还记得前些天的那个火柴棍式的面试题吗?很有趣吧。下面是我今天在StackExchange上看到的一个有趣的面试题。大家不妨一起来思考一下。问题如下——
有两个相同功能代码如下,请在在A,B,C是什么的情况下,请给出三个原因case 1比case 2快,还有三个原因case 2会比case 1要执行的快。(不考虑编译器优化)
for (i=0; i<N; ++i){
A;
B;
C;
}
for (i=0; i<N; ++i){
A;
}
for (i=0; i<N; ++i){
B;
}
for (i=0; i<N; ++i){
C;
}
我的第一个反应是——
case1 要快一些,因为只有一个i++的i<N的操作,而case 2却有三个,这在点上,case 1就比case 2要快。
case2如果要快的话,有一个原因是,A, B, C其中一个需要去先获得一个资源(比如一个锁),在case1下,每次都要去拿这个资源,而case2下,只需要拿一次然后。但这个可能是不对的,因为我无法想出一个相同 ...

使用Flex Bison 和LLVM编写自己的编译器
使用Flex Bison 和 LLVM编写你自己的编译器
原文出处:http://gnuu.org/2009/09/18/writing-your-own-toy-compiler
1、介绍
我总是对编译器和语言非常感兴趣,但是兴趣并不会让你走的更远。大量的编译器的设计概念可以搞的任何一个程序员迷失在这些概念之中。不用说,我也曾今尝试过,但是并没有取得太大的成功,我以前的尝试都停留在语义分析阶段。本文的灵感主要来源于我最近一次的尝试,并且在这一次中我取得一点成就。
幸运的是,最近的几年,我参加了一些项目,这些项目给了我在建立编译器上很多有用的经验和观点。另外一件事是,我非常幸运得到LLVM的帮助。对于这个工具,我不知道改怎么去形容它,但是他给我的这个编译器的确带来非常大的帮助。
1.1、你为什么要阅读本文
你也许想看看我正在做的事情,但是更有可能的是,你也是和我一样对编译器和语言非常感兴趣,并且也可能遇到了一些在探索的过程中遇到了一些难题,你可能正打算解决这些难题,但是却没有发现好的资源。本文的目标就是提供这些资源,并以一种手把手的方式教你从头到尾的去创建一个具有基本功能的语言编 ...
C语言下的错误处理的问题
下面是三种C语言的错误处理,你喜欢哪一种?还是都不喜欢?
/* 问题: 不充分,而且很容易出错,前面成功分配的资源,后面出错需要帮助释放 */
int foo(int bar)
{
int return_value = 0;
int doing_okay = 1;
doing_okay = do_something( bar );
if (doing_okay)
{
doing_okay = init_stuff();
}
if (doing_okay)
{
doing_okay = prepare_stuff();
}
if (doing_okay)
{
return_value = do_the_thing( bar );
}
return return_value;
}
...