我做系统架构的一些原则
工作 20 多年了,这 20 来年看到了很多公司系统架构,也看到了很多问题,在跟这些公司进行交流和讨论的时候,包括进行实施和方案比较的时候,都有很多各种方案的比较和妥协,因为相关的经历越来越多,所以,逐渐形成了自己的逻辑和方法论。今天,想写下这篇文章,把我的这些个人的经验和想法总结下来,希望能够让更多的人可以参考和借鉴,并能够做出更好的架构来。另外,我的这些思维方式和原则都针对于现有市面上众多不合理的架构和方案,所以,也算是一种“纠正”……(注意,这篇文章所说的这些架构上的原则,一般适用于相对比较复杂的业务,如果只是一些简单和访问量不大的应用,那么你可能会得出相反的结论)
目录
原则一:关注于真正的收益而不是技术本身
原则二:以应用服务和 API 为视角,而不是以资源和技术为视角
原则三:选择最主流和成熟的技术
原则四:完备性会比性能更重要
原则五:制定并遵循服从标准、规范和最佳实践
原则六:重视架构扩展性和可运维性
原则七:对控制逻辑进行全面收口
原则八:不要迁就老旧系统的技术债务
原则九:不要依赖自己的 ...

分布式系统的事务处理
当我们在生产线上用一台服务器来提供数据服务的时候,我会遇到如下的两个问题:
1)一台服务器的性能不足以提供足够的能力服务于所有的网络请求。
2)我们总是害怕我们的这台服务器停机,造成服务不可用或是数据丢失。
于是我们不得不对我们的服务器进行扩展,加入更多的机器来分担性能上的问题,以及来解决单点故障问题。 通常,我们会通过两种手段来扩展我们的数据服务:
1)数据分区:就是把数据分块放在不同的服务器上(如:uid % 16,一致性哈希等)。
2)数据镜像:让所有的服务器都有相同的数据,提供相当的服务。
对于第一种情况,我们无法解决数据丢失的问题,单台服务器出问题时,会有部分数据丢失。所以,数据服务的高可用性只能通过第二种方法来完成——数据的冗余存储(一般工业界认为比较安全的备份数应该是3份,如:Hadoop和Dynamo)。 但是,加入更多的机器,会让我们的数据服务变得很复杂,尤其是跨服务器的事务处理,也就是跨服务器的数据一致性。这个是一个很难的问题。 让我们用最经典的Use Case:“A帐号向B帐号汇钱”来说明一下,熟悉RDBMS事务的都知道从帐号A到帐号B需要6个操作:
从A帐 ...
7个示例科普CPU Cache
(感谢网友 @我的上铺叫路遥 翻译投稿)
CPU cache一直是理解计算机体系架构的重要知识点,也是并发编程设计中的技术难点,而且相关参考资料如同过江之鲫,浩瀚繁星,阅之如临深渊,味同嚼蜡,三言两语难以入门。正好网上有人推荐了微软大牛Igor Ostrovsky一篇博文《漫游处理器缓存效应》,文章不仅仅用7个最简单的源码示例就将CPU cache的原理娓娓道来,还附加图表量化分析做数学上的佐证,个人感觉这种案例教学的切入方式绝对是俺的菜,故而忍不住贸然译之,以飨列位看官。
原文地址:Gallery of Processor Cache Effects
大多数读者都知道cache是一种快速小型的内存,用以存储最近访问内存位置。这种描述合理而准确,但是更多地了解一些处理器缓存工作中的“烦人”细节对于理解程序运行性能有很大帮助。
在这篇博客中,我将运用代码示例来详解cache工作的方方面面,以及对现实世界中程序运行产生的影响。
下面的例子都是用C#写的,但语言的选择同程序运行状况以及得出的结论几乎没什么影响。
目录
示例1:内存访问和运行 ...
需求变化与IoC
【感谢 Todd投递本文 – 微博帐号:@weidagang 】
需求又变了,怎么办?
先上一个轻松的段子:
程序员XX遭遇车祸成植物人,医生说活下来的希望只有万分之一,唤醒更为渺茫。可他的Lead和亲人没有放弃,他们根据XX工作如命的作风,每天都在他身边念:“XX,需求又改了,该干活了,你快来呀!”,奇迹终于发生了,XX醒来了,第一句话:“需求又改了?”。
这个段子用幽默的方式反映了需求变化是每一个程序员、架构师或项目经理都会经常遇到的问题。面对这个问题,不同的人有不同的应对之道,最近微博上有一段关于需求变化的讨论:
@假装刺猬的猪:我们在软件开发过程中,会持续碰到客户需求变更的情况。如果没有领域建模,我们单纯将问题使用直觉将问题解决,那么等到客户需求变更或者有新的需求时,就会面临一个僵硬的前设计!无法在以前的设计上持续深入的优化模型,导致需求变更无法及时深化。设计实现均滞后与变更!
@高煥堂: <碰到客户需求变更的情况>是合理的;但<领域建模>不是美好的手段!!!
@weidagang: 要不被客户牵着鼻子走,需要自己有很强的设计能力,反过来 ...
多版本并发控制(MVCC)在分布式系统中的应用
【感谢 Todd投递本文 – 微博帐号:weidagang 】
目录
问题
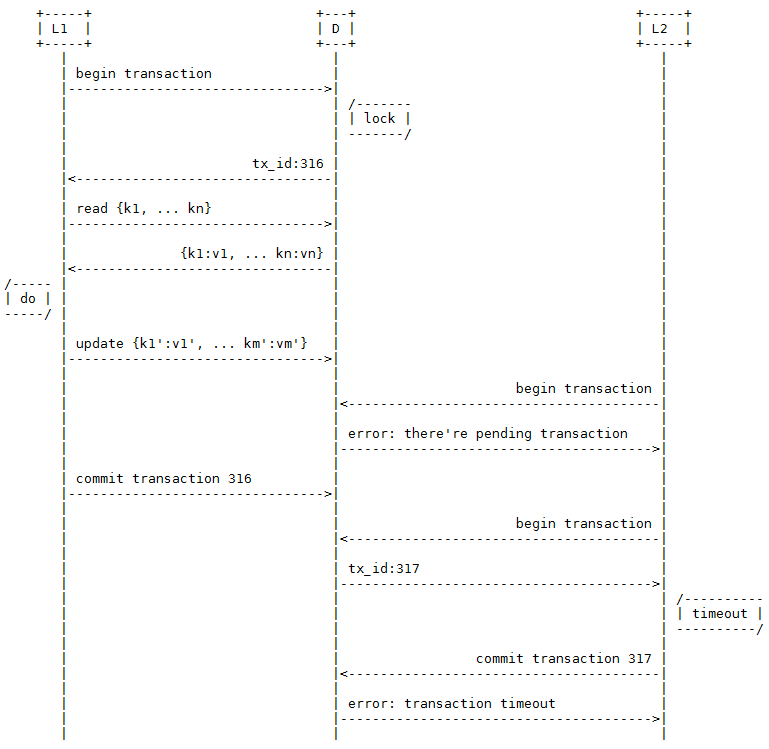
解决方案1:基于锁的事务
解决方案2:多版本并发控制
悲观锁和MVCC对比
总结
参考
友情推荐
问题
最近项目中遇到了一个分布式系统的并发控制问题。该问题可以抽象为:某分布式系统由一个数据中心D和若干业务处理中心L1,L2 … Ln组成;D本质上是一个key-value存储,它对外提供基于HTTP协议的CRUD操作接口。L的业务逻辑可以抽象为下面3个步骤:
read: 根据keySet {k1, … kn}从D获取keyValueSet {k1:v1, … kn:vn}
do: 根据keyValueSet进行业务处理,得到需要更新的数据集keyValueSet’ {k1′:v1′, … km’:vm’} (注:读取的keySet和更新的keySet’可能不同)
update: 把keyValueSet’更新到D (注:D保证在一次调用更新多个key的原子性)
在没有事务支持的情况下,多个L进行并发处理可能会导致数据一致性 ...