编程能力与编程年龄
程序员这个职业究竟可以干多少年,在中国这片神奇的土地上,很多人都说只能干到30岁,然后就需要转型,就像《程序员技术练级攻略》这篇文章很多人回复到这种玩法会玩死人的一样。我在很多面试中,问到应聘者未来的规划都能听到好些应聘都说程序员是个青春饭。因为,大多数程序员都认为,编程这个事只能干到30岁,最多35岁吧。每每我听到这样的言论,都让我感到相当的无语,大家都希望能像《21天速成C++》那样速成,好多时候超级有想和他们争论的冲动,但后来想想算了,因为你无法帮助那些只想呆在井底思维封闭而且想走捷径速成的人。
今天,我们又来谈这个老话题,因为我看到一篇论文,但是也一定会有很多人都会找出各种理由来论证这篇论文的是错的,无所谓了,我把这篇文章送给那些和我一样准备为技术和编程执着和坚持的人。
目录
论文
年龄分布图
能力和年龄分布图
年纪大的人是否跟不上新技术
结论
我的一些感受
论文
首先,我们先来看一篇论文《Is Programming Knowledge Related to Age? ...
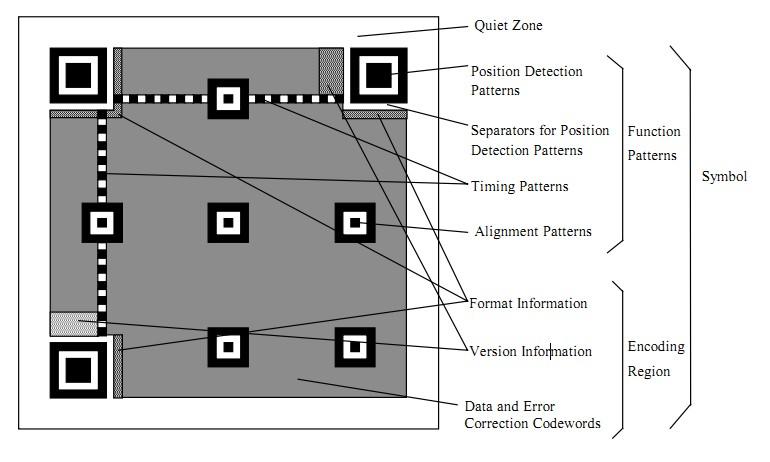
二维码的生成细节和原理
二维码又称QR Code,QR全称Quick Response,是一个近几年来移动设备上超流行的一种编码方式,它比传统的Bar Code条形码能存更多的信息,也能表示更多的数据类型:比如:字符,数字,日文,中文等等。这两天学习了一下二维码图片生成的相关细节,觉得这个玩意就是一个密码算法,在此写一这篇文章 ,揭露一下。供好学的人一同学习之。
关于QR Code Specification,可参看这个PDF:http://raidenii.net/files/datasheets/misc/qr_code.pdf
目录
基础知识
定位图案
功能性数据
数据码和纠错码
数据编码
示例一:数字编码
示例二:字符编码
结束符和补齐符
按8bits重排
补齐码(Padding Bytes)
纠错码
最终编码
穿插放置
Remainder Bits
画二维码图 ...

数据的游戏:冰与火
我对数据挖掘和机器学习是新手,从去年7月份在Amazon才开始接触,而且还是因为工作需要被动接触的,以前都没有接触过,做的是需求预测机器学习相关的。后来,到了淘宝后,自己凭兴趣主动地做了几个月的和用户地址相关数据挖掘上的工作,有一些浅薄的心得。下面这篇文章主要是我做为一个新人仅从事数据方面技术不到10个月的一些心得,也许对你有用,也许很傻,不管怎么样,欢迎指教和讨论。
另外,注明一下,这篇文章的标题模仿了一个美剧《权力的游戏:冰与火之歌》。在数据的世界里,我们看到了很多很牛,很强大也很有趣的案例。但是,数据就像一个王座一样,像征着一种权力和征服,但登上去的路途一样令人胆颤。
目录
数据挖掘中的三种角色
数据的质量
案例一:数据的标准
案例二:数据的准确
数据的业务场景
数据的分析结果
总结
数据挖掘中的三种角色
在Amazon里从事机器学习的工作时,我注意到了Amazon玩数据的三种角色。
Data Analyzer:数据分析员。这类人的人主要是分析数据的,从数据中找到一些规 ...

“作环保的程序员,从不用百度开始”
酷壳对来自百度搜索引擎的访问会弹窗,但是我的这个行为发酵出了一些事情,这里把这个事情说明如下,我会更新相关的东西。内行看门道,外行看热闹。
事由
2月6日 看到梁斌同学的微博(起因可能是因为梁斌同学在微博上对帮助百度的一些工程师们说话导致他的“微博寻人”全站被百度屏蔽)
我看到后,觉得梁斌同学有点太看重被百度收录了,没有站长应该有的气质,所以,我回了一个微博——
“我的酷壳倒反而因为被百度收录而感到掉价!”
2月6日当天,我给coolshell做了个弹窗,并发布微博—— (该微博目前已被新浪管理员删除,后面有说明)
“搞定收工!从百度访问过来的访问弹出对话框。(CoolShell上的网页有缓存,要过些时间才有效)”
2月21日:百度的法律顾问发来邮件。
From: [email protected]
To: [email protected]
CC: [email protected]
Subject: 答复: 网站coolshell.cn弹窗事宜
Date: Thu, 21 Feb 2013 07:05: ...

程序算法与人生选择
每年一到要找工作的时候,我就能收到很多人给我发来的邮件,总是问我怎么选择他们的offer,去腾讯还是去豆瓣,去外企还是去国内的企业,去创业还是去考研,来北京还是回老家,该不该去创新工场?该不该去thoughtworks?……等等,等等。今年从7月份到现在,我收到并回复了60多封这样的邮件。我更多帮他们整理思路,帮他们明白自己最想要的是什么。(注:我以后不再回复类似的邮件了)。
我深深地发现,对于我国这样从小被父母和老师安排各种事情长大的人,当有一天,父母和老师都跟不上的时候,我们几乎完全不知道怎么去做选择。而我最近也离开了亚马逊,换了一个工作。又正值年底,就像去年的那篇《三个故事和三个问题》一样,让我想到写一篇这样的文章。
目录
几个例子
排序算法
贪婪算法
动态规划
Dijkstra最短路径
算法就是Trade-Off
几个例子
当我们在面对各种对选择的影响因子的时候,如:城市,公司规模,公司性质,薪水,项目,户口,技术,方向,眼界…… 你总会发现,你会在几个公司中纠结一些东西,举几个例子:
某网友和我说, ...
如何测试洗牌程序
我希望本文有助于你了解测试软件是一件很重要也是一件不简单的事。
我们有一个程序,叫ShuffleArray(),是用来洗牌的,我见过N多千变万化的ShuffleArray(),但是似乎从来没人去想过怎么去测试这个算法。所以,我在面试中我经常会问应聘者如何测试ShuffleArray(),没想到这个问题居然难倒了很多有多年编程经验的人。对于这类的问题,其实,测试程序可能比算法更难写,代码更多。而这个问题正好可以加强一下我在《我们需要专职的QA吗?》中我所推崇的——开发人员更适合做测试的观点。
我们先来看几个算法(第一个用递归二分随机抽牌,第二个比较偷机取巧,第三个比较通俗易懂)
目录
递归二分随机抽牌
快排Hack法
大多数人的实现
如何测试
正确的算法
如何写测试案例
注意
附录
递归二分随机抽牌
有一次是有一个朋友做了一个网页版的扑克游戏,他用到的算法就是想模拟平时我们玩牌时用手洗牌的方式,是用递归+二分法,我说这个程序恐怕不对吧。他觉得挺对的,说测试了没有问题。他的程序大致如下(原来的是用Java ...
TF-IDF模型的概率解释
(感谢 @猫叔shiro(以前的todd) 投递此文)
目录
信息检索概述
tf-idf模型
信息检索问题的概率视角
盒子小球模型
文档先验概率P(d)与PageRank
词的先验概率P(w)
词代表文档主题的条件概率P(w | d)
词的信息量和idf
多关键词
总结
信息检索概述
信息检索是当前应用十分广泛的一种技术,论文检索、搜索引擎都属于信息检索的范畴。通常,人们把信息检索问题抽象为:在文档集合D上,对于由关键词w[1] … w[k]组成的查询串q,返回一个按查询q和文档d匹配度relevance(q, d)排序的相关文档列表D’。
对于这一问题,先后出现了布尔模型、向量模型等各种经典的信息检索模型,它们从不同的角度提出了自己的一套解决方案。布尔模型以集合的布尔运算为基础,查询效率高,但模型过于简单,无法有效地对不同文档进行排序,查询效果不佳。向量模型把文档和查询串都视为词所构成的多维向量,而文档与查询的相关性即对应于向量间的夹角。不过,由于通常词的数量巨大,向量维度非常高,而大量 ...

xkcd 神图“Click and Drag”
xkcd对于经常浏览国外网站的朋友一定不会陌生。不过,还是先让我来介绍一下xkcd(维基百科词条)。这是一个漫画网站,它主要是发布一些很简单的随手画的漫画,它主要有四种体裁——浪漫、讽刺、数学 和 语言。也会经常出现一些和IT有关的漫画,比如下面这个漫画—— (懂Unix的人一眼就看懂了,不懂的怎么看也看不懂)
本质上来说,xkcd是一种Geek文化,里面的东西都非常的Geek和晦涩,讽刺很辛辣,但很多只有特定人群可以看得懂。而且表达的形式自由到天马行空,飘忽不定。
xkcd.com的网站创建者、所有的漫画的作者叫Randall Munroe,他以前在 NASA工作,是那里的Roboticist——机器人专家,80后,同样,也是一个程序员。他还会画漫画。
xkcd是他于2005年创建的,他本来只是想把他大学里在记事本里画的漫画放到他的个人主页上,但结果却搞成了一个独立的以漫画为主的网站,他用他画的这些漫画做成T恤卖。为什么要取名叫xkcd,据Munroe说,这四个字母,没有任何意义,就是为了让人不能把他们通过拼成一个单词读出来。现在他全职在搞xkcd.com。他现在一周会更新三次 ...

Bret Victor – Learnable Programming
大家是否还记得之前酷壳向大家介绍的苹果设计师Bret Victor一种可视编程的视频《Bret Victor – Inventing on Principle》,最近,他写了一篇文章—— Learnable Programming,写这篇文章的原因是因为“可汗学院(Khan Academy)”近期上线的一个在线编程环境,根据他的演讲提供了一堆基于Javascript的“实时编程”的环境,因为这个环境是引用了他的想法,所以,他有必要出来喷两句。
这篇文章的开头就是一个问题——“How do we get people to understand programming?”,我们怎么让人们懂得编程?
然后,他说了两条——
编程是一种思考,而不是一种死记硬背的技能!你学会了“for循环”并不是说你就学会了编程,这就好像你知道有铅笔这个东西,但是你对绘画还是什么不懂。(对于这一条,正好这两天我在微博上和人辩论“基础算法面试题是否好”(还有微博一,微博二),而且我以前也写过一篇《为什么我反对纯算法面试》,这里借用Bret的话再加强一下我的观点——“我们一方面在骂中国的应试教育毁了学生,另 ...
对九个超级程序员的采访
原文:《Q&A With Nine Great Programmers》时间有限,我只能粗译,难免错误。
这篇访谈源自2006年,最先发布在波兰程序员 Jaroslaw “sztywny” Rzeszótko (AKA “Stiff”) 的博客上。但是这篇博文现在找不到了。非常感谢他能授权我重新发布这个博文。
在一个炎热无聊的下午,我突发奇想。我想通过电子邮件的方式对那些我非常感兴趣和非常敬重的程序员问10个问题。准备这10个问题我只花了5分钟,这些都是我个人想问他们的问题,所以,我基本上没想太多要问他们什么。最后两个问题和编程没有什么关系,我就是想问题这些人的一些兴趣爱好。另外,不是每一个人都想回答我的,这是我第一次做“访谈”,所以,我犯了一些错误,一些问题没有得到回答。不管怎么样,我得到了很多很有意思的内容,所以,这对我绝对是一次很有意义的经历。
并不是每一个人都回了我的邮件,也并不是每一个人都同意回答我的这些问题,也许在我发布这篇文章后我会得到那些回答,但是我已经迫不及待想把这些东西发布了,所以,我可能会更新这篇文章(更新:2006年3月8日,我收到了Bjarne St ...

“单元测试要做多细?”
这篇文章主要来源是StackOverflow上的一个回答——“How deep are your unit tests?”。一个有13.8K的分的人(John Nolan)问了个关于TDD的问题,这个问题并不新鲜,最亮的是这个问题的Best Answer,这个问题是——
“TDD需要花时间写测试,而我们一般多少会写一些代码,而第一个测试是测试我的构造函数有没有把这个类的变量都设置对了,这会不会太过分了?那么,我们写单元测试的这个单元的粒度到底是什么样的?并且,是不是我们的测试测试得多了点?”
答案
StackOverflow上,这个问题的答案是这样的——
“I get paid for code that works, not for tests, so my philosophy is to test as little as possible to reach a given level of confidence (I suspect this level of confidence is high compared to industry standards, but tha ...

GCC 用 C++ 来编译
GCC在2012年8月15日的时候,merge了一个patch – Merge from cxx-conversion branch,这意味着,以后在GCC的编译只能用C++的编译器了,也意味着,gcc的实现代码开始转向C++了。
你可能会有两个问题,
一个问题是为什么GCC要转成C++的实现?
没有C++的编译器,我怎么编译C++编译器的代码?这不是“鸡生蛋还是蛋生鸡”的问题么?
那,我们来看一看吧。
为什么要用C++
在GNU的C++ Conversion文档中,我们可以在Background中看到这样的描述:
Whether we use C or C++, we need to try to ensure that interfaces are easy to understand, that the code is reasonably modular, that the internal documentation corresponds to the code, that it is possi ...
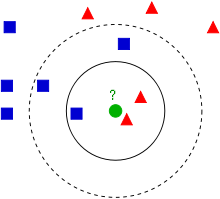
K Nearest Neighbor 算法
K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KNN算法是相对比较容易理解的算法。其中的K表示最接近自己的K个数据样本。KNN算法和K-Means算法不同的是,K-Means算法用来聚类,用来判断哪些东西是一个比较相近的类型,而KNN算法是用来做归类的,也就是说,有一个样本空间里的样本分成很几个类型,然后,给定一个待分类的数据,通过计算接近自己最近的K个样本来判断这个待分类数据属于哪个分类。你可以简单的理解为由那离自己最近的K个点来投票决定待分类数据归为哪一类。
Wikipedia上的KNN词条中有一个比较经典的图如下:
从上图中我们可以看到,图中的有两个类型的样本数据,一类是蓝色的正方形,另一类是红色的三角形。而那个绿色的圆形是我们待分类的数据。
如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
我们可以看 ...
对技术的态度
最近人品爆发,图灵社区,InfoQ,51CTO相继对我做了采访,前两天我把InfoQ对我的采访张贴了出来,今天,图灵社区和51CTO对我的采访发布了(图灵的访谈 ,51CTO的访谈),我是一个有技术焦虑症的人,我的经历比较特殊,对大家来说可能也没有什么意思,这两个采都有一些重叠的部分,不过有些观点我想再加强一些,并放在这里和大家一起分享一下。
目录
对于日新月异的新技术,你是什么态度?
可是在应用环境中,对新技术的需求是很高的,你觉得在教育领域计算机科学的侧重应该是什么样的?
那么,现在做一个软件开发者是否更加困难了?
你如何在进度压力下,享受技术带来的快乐?
对于日新月异的新技术,你是什么态度?
遇到新技术我会去了解,但不会把很大的精力放在这些技术(如:NoSQL,Node.js,等)。这些技术尚不成熟,只需要跟得住就可以了。技术十年以上可能是一个门槛。有人说技术更新换代很快,我一点儿都不觉得是这样想。虽然有不成熟的技术不断地涌出,但是成熟的技术,比如Unix,40多年,C,40多年,C++,30多年,TCP/I ...
InfoQ的ArchSummit大会对我的采访
偷个懒,做个更新,今天下午InfoQ的ArchSummit对我的一些采访。我整理了一下,算做是我个人写酷壳的一些想法和总结。不过问我的这些问题并不尖锐,呵呵,不像@图灵谢工 问我的问题:“你的价值观太过理想,根本不现实,你站在道德的高点拷问社会,是不是想炒作自己?”。
1) 作为酷壳的博主,请您大概介绍下酷壳是什么时候开始的,初衷是什么 ?
我写blog是从2002年开始(那时还没有blog这个词),当时对我来说,没有自己的电脑,上网很不方便,而我有写学习笔记的习惯,读书和工作中学到的一些东西需要保存在某个地方,我希望这个地方可以让我在任何地方都可以调出来看看(因为我当时的工作出差太多),正好当时的CSDN有个“专家专栏”的功能,也就是后来出现的blog。
后来Blog出现后,CSDN把自己的“专家专栏”全部迁移到了blog.csdn.net上,07-08年这段时间,CSDN的blog基本上是不能使用,性能差得不能再差,每天宕机,上传图片,贴代码,都非常不好用。也许,这就是使用.NET/Windows平台的问题(开个玩笑)。
我是从2009年3月开始创建酷壳的,创建的初衷 ...

代码执行的效率
在《性能调优攻略》里,我说过,要调优性需要找到程序中的Hotspot,也就是被调用最多的地方,这种地方,只要你能优化一点点,你的性能就会有质的提高。在这里我给大家举三个关于代码执行效率的例子(它们都来自于网上)
第一个例子
PHP中Getter和Setter的效率(来源reddit)
这个例子比较简单,你可以跳过。
考虑下面的PHP代码:我们可看到,使用Getter/Setter的方式,性能要比直接读写成员变量要差一倍以上。
<?php
//dog_naive.php
class dog {
public $name = "";
public function setName($name) {
$this->name = $name;
}
public function getName() {
return $this->name;
}
}
$rover = new dog();
//通过Getter/Setter方式
for ($x=0; $x<10; $x++) {
$t ...
28个Unix/Linux的命令行神器
下面是Kristóf Kovács收集的28个Unix/Linux下的28个命令行下的工具(原文链接),有一些是大家熟悉的,有一些是非常有用的,有一些是不为人知的。这些工具都非常不错,希望每个人都知道。本篇文章还在Hacker News上被讨论,你可以过去看看。我以作者的原文中加入了官网链接和一些说明。
目录
dstat & sar
slurm
vim & emacs
screen, dtach, tmux, byobu
multitail
tpp
xargs & parallel
duplicity & rsyncrypto
nethack & slash’em
lftp
ack
calcurse & remind + wyrd
newsbeuter & rsstail
powertop
htop & iotop
ttyrec & ipbt
...

关于闰秒
2012年6月30日,也就今天晚上,时间会多出现一秒,也就是我们所说的闰秒。我不知道大家对闰秒的了解有多少,所以写下这篇文章。
背景知识
闰秒是在在UTC(中文“世界标准时间”或“世界协调时间”/英文“Coordinated Universal Time”/法文“Temps Universel Cordonné”)是基于Atomic Clock(原子时钟)的一种时间,向太阳时(Solar Time )对齐的一种方法,因为太阳时是根据地球公转来计算的。所以,1972年制定的UTC为了确保其时间相对于UTC的时间误差不能超过0.9秒,因此在过一段时间后需要加一秒。下图是有UTC以来闰秒的调整表(来自Wikipedia闰秒的中文词条)
从上表中我们可以看到,从1972年到现在,在这四十年里已经进行过25次的闰秒调整。闰秒是在每年6月或12月的最后一天的最后一分钟进行跳秒或不跳秒。是否加入闰秒由位于巴黎的国际地球自转和参考坐标系统服务(IERS – International Earth Rotation and Reference Systems ...
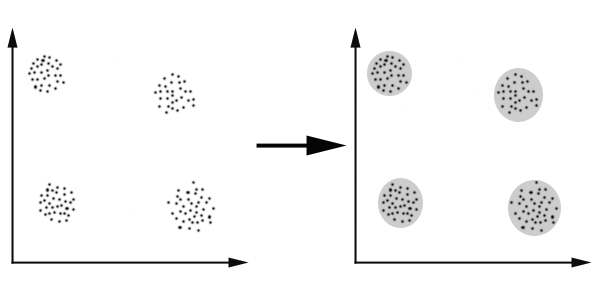
K-Means 算法
最近在学习一些数据挖掘的算法,看到了这个算法,也许这个算法对你来说很简单,但对我来说,我是一个初学者,我在网上翻看了很多资料,发现中文社区没有把这个问题讲得很全面很清楚的文章,所以,把我的学习笔记记录下来,分享给大家。
在数据挖掘中, k-Means 算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。
目录
问题
算法概要
求点群中心的算法
K-Means的演示
K-Means ++ 算法
K-Means 算法应用
问题
K-Means算法主要解决的问题如下图所示。我们可以看到,在图的左边有一些点,我们用肉眼可以看出来有四个点群,但是我们怎么通过计算机程序找出这几个点群来呢?于是就出现了我们的K-Means算法(Wikipedia链接)
K-Means 要解决的问题
算法概要
这个算法其实很简单,如下图所示:
K-Means 算法概要
从上图中,我们可以看到,A, B, ...

Git显示漂亮日志的小技巧
原文:http://garmoncheg.blogspot.com/2012/06/pretty-git-log.html (墙)
Git的传统log如下所示,你喜欢吗?
看看下面这个你喜不喜欢?(点击图片看大图)
要做到这样,命令行如下:
git log --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit --
这样有点长了,我们可以这样:
git config --global alias.lg "log --color --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit --"
然后,我们就可以使用这样的短命令了:
git lg
如果你想看看git log –prett ...