如何读懂并写出装逼的函数式代码
今天在微博上看到了 有人分享了下面的这段函数式代码,我把代码贴到下面,不过我对原来的代码略有改动,对于函数式的版本,咋一看,的确令人非常费解,仔细看一下,你可能就晕掉了,似乎完全就是天书,看上去非常装逼,哈哈。不过,我感觉解析那段函数式的代码可能会一个比较有趣过程,而且,我以前写过一篇《函数式编程》的入门式的文章,正好可以用这个例子,再升华一下原来的那篇文章,顺便可以向大家更好的介绍很多基础知识,所以写下这篇文章。
目录
先看代码
Javascript的箭头函数
匿名函数的递归
动用高阶函数的递归
回顾之前的程序
其它
先看代码
这个代码平淡无奇,就是从一个数组中找到一个数,O(n)的算法,找不到就返回 null。
下面是正常的 old-school 的方式。不用多说。
//正常的版本
function find (x, y) {
for ( let i = 0; i < x.length; i++ ) {
if ( x[i] == y ) return i;
}
return null ...
二维码的生成细节和原理
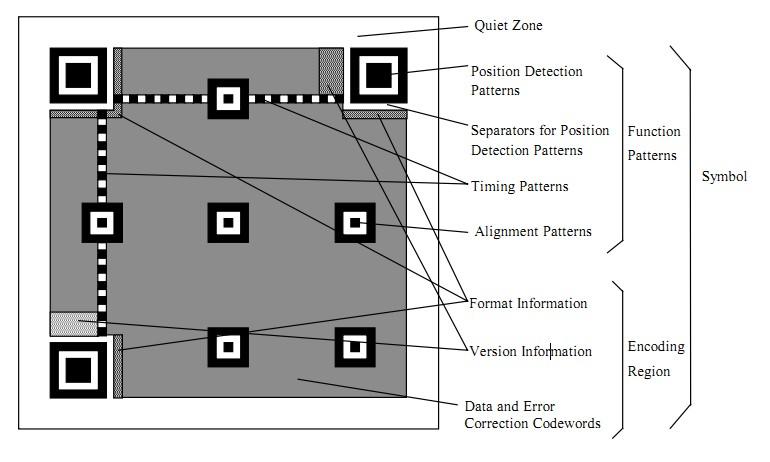
二维码又称QR Code,QR全称Quick Response,是一个近几年来移动设备上超流行的一种编码方式,它比传统的Bar Code条形码能存更多的信息,也能表示更多的数据类型:比如:字符,数字,日文,中文等等。这两天学习了一下二维码图片生成的相关细节,觉得这个玩意就是一个密码算法,在此写一这篇文章 ,揭露一下。供好学的人一同学习之。
关于QR Code Specification,可参看这个PDF:http://raidenii.net/files/datasheets/misc/qr_code.pdf
目录
基础知识
定位图案
功能性数据
数据码和纠错码
数据编码
示例一:数字编码
示例二:字符编码
结束符和补齐符
按8bits重排
补齐码(Padding Bytes)
纠错码
最终编码
穿插放置
Remainder Bits
画二维码图 ...
TF-IDF模型的概率解释
(感谢 @猫叔shiro(以前的todd) 投递此文)
目录
信息检索概述
tf-idf模型
信息检索问题的概率视角
盒子小球模型
文档先验概率P(d)与PageRank
词的先验概率P(w)
词代表文档主题的条件概率P(w | d)
词的信息量和idf
多关键词
总结
信息检索概述
信息检索是当前应用十分广泛的一种技术,论文检索、搜索引擎都属于信息检索的范畴。通常,人们把信息检索问题抽象为:在文档集合D上,对于由关键词w[1] … w[k]组成的查询串q,返回一个按查询q和文档d匹配度relevance(q, d)排序的相关文档列表D’。
对于这一问题,先后出现了布尔模型、向量模型等各种经典的信息检索模型,它们从不同的角度提出了自己的一套解决方案。布尔模型以集合的布尔运算为基础,查询效率高,但模型过于简单,无法有效地对不同文档进行排序,查询效果不佳。向量模型把文档和查询串都视为词所构成的多维向量,而文档与查询的相关性即对应于向量间的夹角。不过,由于通常词的数量巨大,向量维度非常高,而大量 ...

Bret Victor – Learnable Programming
大家是否还记得之前酷壳向大家介绍的苹果设计师Bret Victor一种可视编程的视频《Bret Victor – Inventing on Principle》,最近,他写了一篇文章—— Learnable Programming,写这篇文章的原因是因为“可汗学院(Khan Academy)”近期上线的一个在线编程环境,根据他的演讲提供了一堆基于Javascript的“实时编程”的环境,因为这个环境是引用了他的想法,所以,他有必要出来喷两句。
这篇文章的开头就是一个问题——“How do we get people to understand programming?”,我们怎么让人们懂得编程?
然后,他说了两条——
编程是一种思考,而不是一种死记硬背的技能!你学会了“for循环”并不是说你就学会了编程,这就好像你知道有铅笔这个东西,但是你对绘画还是什么不懂。(对于这一条,正好这两天我在微博上和人辩论“基础算法面试题是否好”(还有微博一,微博二),而且我以前也写过一篇《为什么我反对纯算法面试》,这里借用Bret的话再加强一下我的观点——“我们一方面在骂中国的应试教育毁了学生,另 ...
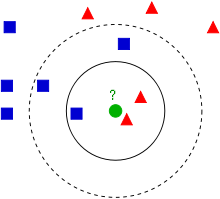
K Nearest Neighbor 算法
K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KNN算法是相对比较容易理解的算法。其中的K表示最接近自己的K个数据样本。KNN算法和K-Means算法不同的是,K-Means算法用来聚类,用来判断哪些东西是一个比较相近的类型,而KNN算法是用来做归类的,也就是说,有一个样本空间里的样本分成很几个类型,然后,给定一个待分类的数据,通过计算接近自己最近的K个样本来判断这个待分类数据属于哪个分类。你可以简单的理解为由那离自己最近的K个点来投票决定待分类数据归为哪一类。
Wikipedia上的KNN词条中有一个比较经典的图如下:
从上图中我们可以看到,图中的有两个类型的样本数据,一类是蓝色的正方形,另一类是红色的三角形。而那个绿色的圆形是我们待分类的数据。
如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
我们可以看 ...
K-Means 算法
最近在学习一些数据挖掘的算法,看到了这个算法,也许这个算法对你来说很简单,但对我来说,我是一个初学者,我在网上翻看了很多资料,发现中文社区没有把这个问题讲得很全面很清楚的文章,所以,把我的学习笔记记录下来,分享给大家。
在数据挖掘中, k-Means 算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。
目录
问题
算法概要
求点群中心的算法
K-Means的演示
K-Means ++ 算法
K-Means 算法应用
问题
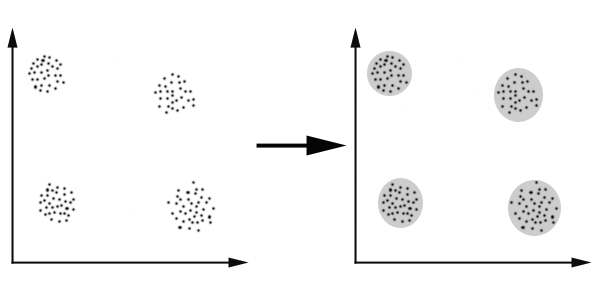
K-Means算法主要解决的问题如下图所示。我们可以看到,在图的左边有一些点,我们用肉眼可以看出来有四个点群,但是我们怎么通过计算机程序找出这几个点群来呢?于是就出现了我们的K-Means算法(Wikipedia链接)
K-Means 要解决的问题
算法概要
这个算法其实很简单,如下图所示:
K-Means 算法概要
从上图中,我们可以看到,A, B, ...

Huffman 编码压缩算法
前两天发布那个rsync算法后,想看看数据压缩的算法,知道一个经典的压缩算法Huffman算法。相信大家应该听说过 David Huffman 和他的压缩算法—— Huffman Code,一种通过字符出现频率,Priority Queue,和二叉树来进行的一种压缩算法,这种二叉树又叫Huffman二叉树 —— 一种带权重的树。从学校毕业很长时间的我忘了这个算法,但是网上查了一下,中文社区内好像没有把这个算法说得很清楚的文章,尤其是树的构造,而正好看到一篇国外的文章《A Simple Example of Huffman Code on a String》,其中的例子浅显易懂,相当不错,我就转了过来。注意,我没有对此文完全翻译。
我们直接来看示例,如果我们需要来压缩下面的字符串:
“beep boop beer!”
首先,我们先计算出每个字符出现的次数,我们得到下面这样一张表 :
字符
次数
‘b’
3
‘e’
4
...

rsync 的核心算法
rsync是unix/linux下同步文件的一个高效算法,它能同步更新两处计算机的文件与目录,并适当利用查找文件中的不同块以减少数据传输。rsync中一项与其他大部分类似程序或协定中所未见的重要特性是镜像是只对有变更的部分进行传送。rsync可拷贝/显示目录属性,以及拷贝文件,并可选择性的压缩以及递归拷贝。rsync利用由Andrew Tridgell发明的算法。这里不介绍其使用方法,只介绍其核心算法。我们可以看到,Unix下的东西,一个命令,一个工具都有很多很精妙的东西,怎么学也学不完,这就是Unix的文化啊。
本来不想写这篇文章的,因为原先发现有很多中文blog都说了这个算法,但是看了一下,发现这些中文blog要么翻译国外文章翻译地非常烂,要么就是介绍这个算法介绍得很乱让人看不懂,还有错误,误人不浅,所以让我觉得有必要写篇rsync算法介绍的文章。(当然,我成文比较仓促,可能会有一些错误,请指正)
目录
问题
算法
rolling checksum算法
图示
问题
首先, 我们先来想一下rsync要解决的问题,如果我们要 ...

挑战无处不在
面试过一些应聘者,当我问到为什么换工作的时候,他们都会告诉我,现在的工作没有挑战,无聊,所以想换一个有挑战的工作。于是我问了一下他的工作情况,发现那些有挑战的东西他还没有搞懂。我总是为有这样的认识的朋友感到惋惜,因为我总是认为有挑战的东西无处不在啊,不能因为工作上没有,自己就放纵了自己。比如,面试过一个做地图的工程师,他的工作是做计算地图上任意两点的最短或最优路径的一部分功能。我觉得这个事很有挑战,也有难度,应聘者说,没什么挑战,因为他做的东西只是调用相关的算法库。他在这个项目干了2年了,当我问他有没有看过算法库,知不知道地图是怎么存储的?他却告诉我,因为没有去做,所以就没有去了解,等做的时候再了解(我希望有这样想法的人都去看看程序员的谎谬之言还是至理名言?)。这样的例子很多,很多应聘者在面试中不能和我一起解决某个问题的时候,比如:OOD,数据库设计,系统设计,等,他们都会告诉我,不好意思,因为没有做过相关的事情,所以就不懂了,所以,他需要一个像我们这样的项目来学习和锻炼。我并不要求你能解决你所不擅长的问题,但毕竟数据库,OO,系统设计都是软件开发的基础知识,多少要懂一些吧。
但另外 ...
由12306.cn谈谈网站性能技术
12306.cn网站挂了,被全国人民骂了。我这两天也在思考这个事,我想以这个事来粗略地和大家讨论一下网站性能的问题。因为仓促,而且完全基于本人有限的经验和了解,所以,如果有什么问题还请大家一起讨论和指正。(这又是一篇长文,只讨论性能问题,不讨论那些UI,用户体验,或是是否把支付和购票下单环节分开的功能性的东西)
目录
业务
前端性能优化技术
一、前端负载均衡
二、减少前端链接数
三、减少网页大小增加带宽
四、前端页面静态化
五、优化查询
六、缓存的问题
后端性能优化技术
一、数据冗余
二、数据镜像
三、数据分区
四、后端系统负载均衡
五、异步、 throttle 和 批量处理
小结
业务
任何技术都离不开业务需求,所以,要说明性能问题,首先还是想先说说业务问题。
其一,有人可能把这个东西和QQ或是网游相比。但我觉得这两者是不一样的,网游和QQ在线或是登录时访问的更多的是用户 ...
如何设计“找回用户帐号”功能
因为《腾讯帐号申诉的用户体验》一文中好多人觉得腾讯申诉是世界级先进的,并让我拿出一个找回用户的帐号的功能来。本来不想写的,因为大家看看其它系统的就行的,但是,很明显有些人就是很懒,也不会思考,而且不会观察,所以,我就只好写下这篇科普性常识性的文章。
在行文之前,我得先感谢腾讯公司的至少30名员工在《腾讯帐号申诉的用户体验》一文后的回帖(我STFG(Search The Fucking Google)看到了你们使用的那个固定IP在各个大学论坛上的腾讯的招聘广告),我感谢你们主要有两点:
你们有半数以上的人留下的是gmail而不是QQMail/Foxmail的电子邮件,这点让我感到很欣慰。
你们在加班到晚上11点的时候都能在本站回复,的确如你们的Andy Pan所说,你们的核心竞争力很强,包括水军方面。
好了,让我正式谈谈这个设计。找回用户帐号通常就用三个事就可以了:邮箱,安全问答,手机。
邮箱,安全问答,手机
大多数的系统都会使用邮箱和安全问答,这足够了,很多系统直接用邮箱做帐号名(Apple ID,Facebook,新浪微博 ….),这样一来,就算你的系统口令被盗,帐号的是改 ...
千万不要把 bool 设计成函数参数
我们有很多Coding Style 或 代码规范。但这一条可能会经常被我们所遗忘,就是我们经常会在函数的参数里使用bool参数,这会大大地降低代码的可读性。不信?我们先来看看下面的代码。
当你读到下面的代码,你会觉得这个代码是什么意思?
widget->repaint(false);
是不要repaint吗?还是别的什么意思?看了文档后,我们才知道这个参数是immediate, 也就是说,false代表不立即重画,true代码立即重画。
Windows API中也有这样一个函数:InvalidateRect,当你看到下面的代码,你会觉得是什么意思?
InvalidateRect(hwnd, lpRect, false);
我们先不说InvalidateRect这个函数名取得有多糟糕,我们先说一下那个false参数?invalidate意为“让XXX无效”,false是什么意思?双重否定?是肯定的意思?如果你看到这样的代码,你会相当的费解的。于是,你要去看一下文档,或是InvalidateRect的函数定义,你会看到那个参数是 BOOL bErase,意思是 ...
排序算法 Sleep Sort
排序算法好像是程序员学习编程最多的算法,也可能是算法研究者们最喜欢研究的算法了。排序有很多很多的算法,比如,冒泡,插入,选择,堆,快速,归并等等(你可以看看本站以前的那些文章:可视化的排序,排序算法比较,显示排序过程的python)这里向大家介绍一个“巨NB”的排序算法——Sleep Sort。
闲言少说,请看下面的代码(用Shell脚本写的)
#!/bin/bash
function f() {
sleep "$1"
echo "$1"
}
while [ -n "$1" ]
do
f "$1" &
shift
done
wait
用法如下:
./sleepsort.bash 5 3 6 3 6 3 1 4 7
相信你可以会去试一下这个脚本,也相你你试完后你一定会说——“我擦,真TMD排序了!”,我还是不要解释这段代码了,过多的解释会不如代码那么直接,而且解释会影响你对这个排序算法的NB性。只想说——这是正二八经的多线程、多进程排序啊。我们的Bogo排序也黯然失色啊。
下面我们需要对这个算法做一些分析——
1)让我们来分析一个这这个程序的算法 ...
可视化的排序过程
下面是一个日本程序员制做的一个可视化的排序过程,包括了各种经典的排序算法,你可以调整速度和需要排序的个数。酷壳以前也介绍过几篇相关的文章 一个排序算法比较的网站,一个显示排序过程的Python脚本 关于各种排序算法的运行复杂度比较,请参看Wikipedia的排序算法比较。
&lt;br /&gt;

用户界面和用户体验的差别
用户界面设计
用户界面设计
用户体验设计
用户体验设计在便池上放一个假苍蝇会导致男人撒尿的时候会不由自主地瞄准它,有证据表明,这样的用户体验可以减少80%的小便溅出便池。

一个在线的画UML图的网站
http://yuml.me/
这个网站可以允许你在线地,通过一些UML的语法,生成相应的图片。
比如,如果你输入:
<img src="http://yuml.me/diagram/class/[Customer]1-0..*[Address]"/>
那么,你就可以得到下面的图片:
如果,我们输入:
<img src="http://yuml.me/diagram/class/
[User|+Forename+;Surname;+HashedPassword;-Salt|+Login();+Logout()]" alt="" />
还有Use Case:
<img src="http://yuml.me/diagram/usecase/[Customer]-(Login), [Customer]-(Logout)"/>
还是挺不错的吧,呵呵。大家可以上去试试。