数据的游戏:冰与火
我对数据挖掘和机器学习是新手,从去年7月份在Amazon才开始接触,而且还是因为工作需要被动接触的,以前都没有接触过,做的是需求预测机器学习相关的。后来,到了淘宝后,自己凭兴趣主动地做了几个月的和用户地址相关数据挖掘上的工作,有一些浅薄的心得。下面这篇文章主要是我做为一个新人仅从事数据方面技术不到10个月的一些心得,也许对你有用,也许很傻,不管怎么样,欢迎指教和讨论。
另外,注明一下,这篇文章的标题模仿了一个美剧《权力的游戏:冰与火之歌》。在数据的世界里,我们看到了很多很牛,很强大也很有趣的案例。但是,数据就像一个王座一样,像征着一种权力和征服,但登上去的路途一样令人胆颤。
目录
数据挖掘中的三种角色
数据的质量
案例一:数据的标准
案例二:数据的准确
数据的业务场景
数据的分析结果
总结
数据挖掘中的三种角色
在Amazon里从事机器学习的工作时,我注意到了Amazon玩数据的三种角色。
Data Analyzer:数据分析员。这类人的人主要是分析数据的,从数据中找到一些规 ...
K Nearest Neighbor 算法
K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KNN算法是相对比较容易理解的算法。其中的K表示最接近自己的K个数据样本。KNN算法和K-Means算法不同的是,K-Means算法用来聚类,用来判断哪些东西是一个比较相近的类型,而KNN算法是用来做归类的,也就是说,有一个样本空间里的样本分成很几个类型,然后,给定一个待分类的数据,通过计算接近自己最近的K个样本来判断这个待分类数据属于哪个分类。你可以简单的理解为由那离自己最近的K个点来投票决定待分类数据归为哪一类。
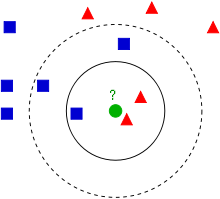
Wikipedia上的KNN词条中有一个比较经典的图如下:
从上图中我们可以看到,图中的有两个类型的样本数据,一类是蓝色的正方形,另一类是红色的三角形。而那个绿色的圆形是我们待分类的数据。
如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
我们可以看 ...
K-Means 算法
最近在学习一些数据挖掘的算法,看到了这个算法,也许这个算法对你来说很简单,但对我来说,我是一个初学者,我在网上翻看了很多资料,发现中文社区没有把这个问题讲得很全面很清楚的文章,所以,把我的学习笔记记录下来,分享给大家。
在数据挖掘中, k-Means 算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。
目录
问题
算法概要
求点群中心的算法
K-Means的演示
K-Means ++ 算法
K-Means 算法应用
问题
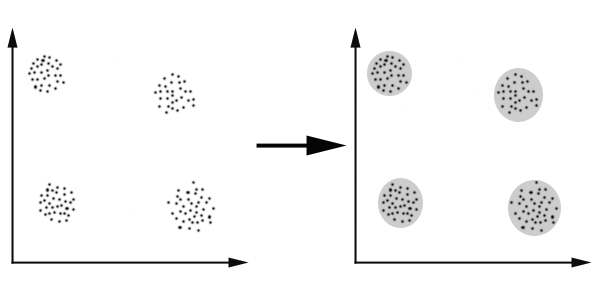
K-Means算法主要解决的问题如下图所示。我们可以看到,在图的左边有一些点,我们用肉眼可以看出来有四个点群,但是我们怎么通过计算机程序找出这几个点群来呢?于是就出现了我们的K-Means算法(Wikipedia链接)
K-Means 要解决的问题
算法概要
这个算法其实很简单,如下图所示:
K-Means 算法概要
从上图中,我们可以看到,A, B, ...